很多 AI 工作流失控,是因為任務交出去時沒有工作環境、上下文邊界和驗收節點。prompt 越堆越長,AI 仍然會忘記規則,輸出看似順滑,卻很難判斷哪裡被改壞。
Harness Engineering 要處理的正是這個問題:把一次性 prompt 變成可重複、可確認、可修正的流程。
什麼是 Harness Engineering?
簡單說,Harness Engineering 是替 AI Agent 設計「任務外骨骼」。模型本身負責推理和生成,但它需要一套外部結構來決定:要讀哪些 context、能改哪些檔案、何時停下來等人確認、用甚麼規則驗收輸出、錯誤要怎樣回流成下一輪限制。
和 prompt engineering 的分別在於,prompt engineering 多數處理單次指令怎樣寫得更清楚;Harness Engineering 處理的是一整條工作流怎樣被固定、監控和逐步改善。
一個實用的 Harness Engineering 流程,通常會包含幾個層次:
- Context boundary:先界定 AI 能讀到甚麼資料。可以是 workspace、文件夾、規則檔、來源資料庫,而不是把所有資料塞進同一段 prompt。
- Task shaping:把大任務拆成可審查的小任務。AI 不直接完成整篇文章,而是先掃描、再 planning、再分段執行。
- HITL control point:在人需要判斷的位置插入停頓。AI 先回報理解、計畫和風險,人確認後才進入下一步。
- Guardrails / evaluation:把「不要亂改」「不要 AI 味」「不要新增事實」拆成可檢查規則,例如 checklist、禁用詞、保留事項和輸出格式。
- Feedback loop:AI 犯過的錯不只靠口頭提醒,而是沉澱成下一輪規則、template,甚至 skill。skill 或 Markdown 規則也不是終點,之後仍要按新錯誤和新場景繼續更新。
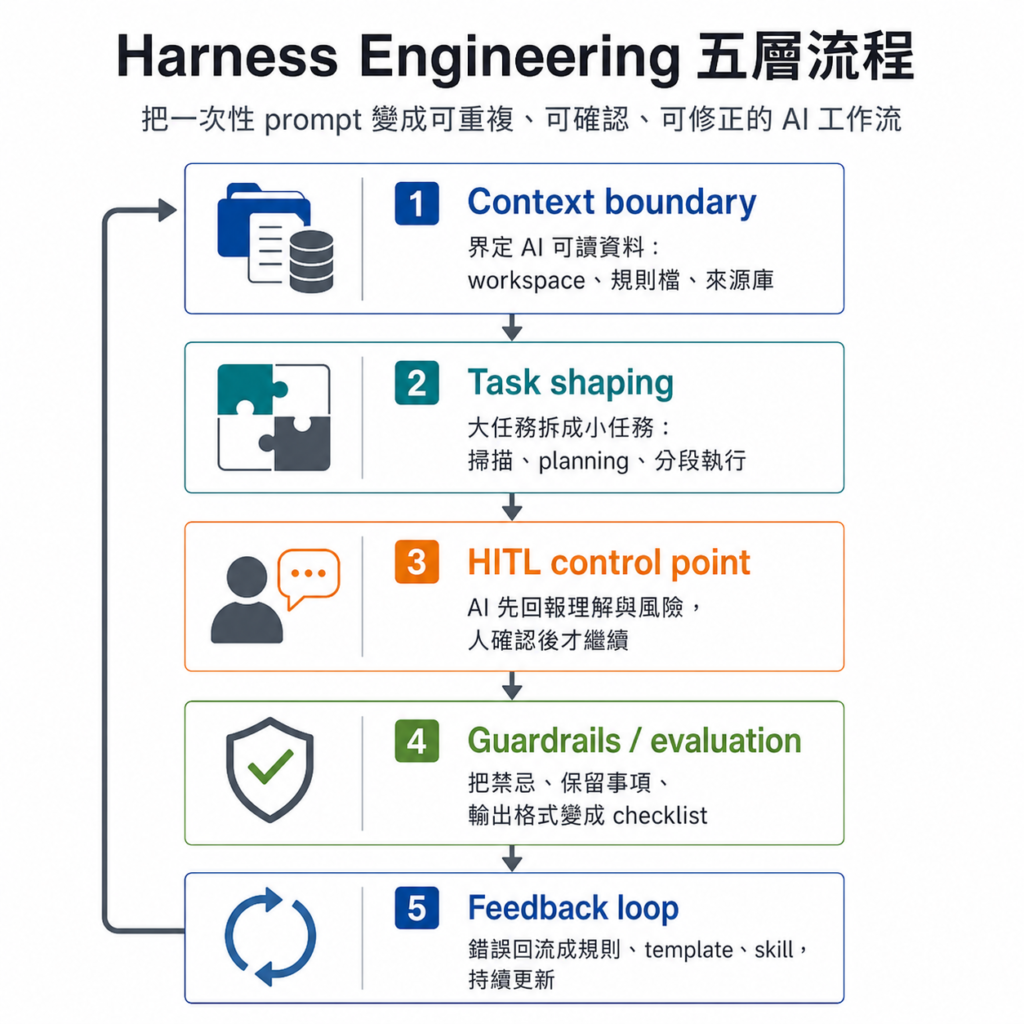
這五步做起來,AI 的角色會從「一次性回答者」變成「在受控流程裡工作的 Agent」。人也不需要每次重新教它,而是逐步把上下文、確認點和驗收口徑固定下來。接著把這套概念壓到一個具體場景:在 Codex App 電腦版改寫一篇有 AI 味的文章,從最小 workspace 長出 HITL、dynamic context loading、checklist、templates 和 skill。
Harness Engineering:示範用Codex App建立 AI 改稿工作流程
如果你只把整篇文章貼進聊天框,再輸入「幫我改自然一點」,AI 只能根據當下那一段對話猜你的意思。它不知道你平時怎樣寫,不知道哪些句子只是語氣問題、哪些資料不能改,也不知道你想保留原文的哪些判斷。Harness Engineering 在這裡的意思,是先給 AI 一個可工作的環境:有原稿、有基本語氣規則、有明確禁用句型,然後在改稿過程中逐步補上驗收標準。
在 Codex App 電腦版裡,不需要一開始就準備完整系統。比較現實的做法,是先建立一個最小文章資料夾:
harness-engineering-article/
draft.md
style-guide.md
forbidden-phrases.md
你可以在左側 workspace 開啟這個資料夾,把原本有 AI 味的文章放進 draft.md,再用 style-guide.md 寫 5 至 8 條語氣規則。forbidden-phrases.md 用來放「在這個數位時代」、「不可否認的是」、「總而言之」這類不要出現的句型。
先跑一輪改稿後,如果你發現 AI 常常刪掉例子、加入來源沒有的判斷,或者把文章改成中立報告口吻,再把這些問題沉澱成 rewrite-checklist.md。如果文章需要保留引用、數字或來源脈絡,才補 source-database.md。
先界定 AI 能讀到的工作範圍,任務就不會散落在一次對話裡。第一次叫 Codex 讀資料夾時,不要急著要求它改文。先讓它自己掃描 workspace,列出它看到的檔案,並說明準備怎樣使用;你確認後,它才可以進入改寫。
請先掃描這個 workspace。
現在不要改寫正文。
請先回報:
1. 你看到哪些 Markdown 檔案
2. 你判斷每個檔案在改稿中應該扮演甚麼角色
3. 這篇文章最需要保留的資訊
4. 這篇文章最像 AI 寫作的問題
5. 你建議先改哪一小段,以及為甚麼
回報後請停下來,等我確認。這一步做完,讀者應該看到 Codex 回報它讀到哪些檔案、理解了哪些限制,以及準備先處理哪一小段。
這裡的重點是 HITL:Human-in-the-loop。人不是等 AI 改完全文才審,而是在 AI 動手前先確認它讀對資料、抓對問題、選對第一步。
這就是工具文裡最實際的 Harness:不是一開始設計一套巨型流程,而是先讓 AI 在最小可控環境裡工作,再把實戰中反覆出現的錯誤變成新規則。
Workspace:它決定 AI 能看見甚麼、能改甚麼
建立了資料夾後,我們要考慮 AI 要讀哪些 context (檔案)。
Codex App 的 workspace 不是單純收納檔案的資料夾。它是 AI 讀取上下文的範圍。你把 draft.md 放進去,AI 才能讀原稿;你把 style-guide.md 放進去,AI 才能對照你的語氣;你把禁用句型分開,AI 才能逐項檢查,而不是把所有規則塞進一次 prompt 裡。這比一直複製貼上穩定,因為每次任務都能回到同一批檔案。
你不是要求模型「記住所有東西」,而是把需要記住的規則放到本機檔案,讓 AI 在不同階段重新讀取。上下文被固定下來,後面的改稿才有同一套依據。
以下繼續示範”去AI味改寫流程”。
style-guide.md 不需要寫得像一本手冊。初學者可以先放 5 至 8 條具體規則,例如:
# style-guide.md
- 用繁體中文。
- 句子要短,但不要刪掉必要例子。
- 優先寫具體操作,不寫抽象口號。
- 避免「不是 X,而是 Y」句型。
- 解釋工具時,要寫出讀者按哪裡、輸入甚麼、系統會顯示甚麼。
- 保留作者原本的判斷,不要改成中立報告口吻。forbidden-phrases.md 可以更直接,只列不要出現的詞和句型。不要只放幾句老套開場,也要放 AI 常見的對仗句、假深度句和空泛收束句:
# forbidden-phrases.md
- 在這個數位時代
- 隨著科技日新月異
- 人工智慧正以前所未有的速度
- 不可否認的是
- 總而言之
- 值得注意的是
- 將為我們帶來無限可能
- 讓我們拭目以待
## 對仗句 / 排比句
- 不是取代人類,而是賦能人類
- 不是工具升級,而是思維轉變
- 既要保持效率,也要兼顧品質
- 從工具使用者,變成流程設計者
- 由點到面,從局部到全局
## 假深度 / 空泛收束
- 真正重要的不是技術本身,而是我們如何使用它
- 關鍵在於找到人與 AI 之間的平衡
- 這將重新定義我們與 AI 協作的方式
- 未來的競爭,不再只是技術的競爭
- 只有理解底層邏輯,才能真正駕馭工具
## AI 常見轉折
- 然而,這並不意味著
- 換句話說
- 更進一步來看
- 從某種程度上說
- 這也提醒我們然後在 Codex App 的輸入框貼這段 prompt:
請檢查 workspace 的最小寫作規則。
請自行找出 workspace 裡與寫作風格、禁用句型有關的 Markdown 檔案。
請不要改 draft.md。
請先判斷這些規則是否足夠讓你改寫 draft.md 的第一輪。
如果不足夠,請列出還缺甚麼規則。
如果足夠,請用表格列出:
- 規則檔案
- 你會怎樣使用它
- 改寫時最容易違反的地方
列完後請停下來,等我確認。這裡要小心一件事:規則檔不是越長越好。太長的規則會擠壓上下文,AI 反而抓不到重點。比較好的做法,是把 style-guide.md 寫成方向,把 forbidden-phrases.md 寫成明確禁用句。當 AI 改錯方向時,你再補 rewrite-checklist.md;當同一套流程跑過幾篇文章後,再抽成 style-guide-template.md、rewrite-plan-template.md 或 context-load-prompt.md。好的 harness 不是一次設計完,它是從實際錯誤和重複動作裡長出來的。
長任務還有一個常見問題:AI 會在後面幾輪忘記前面的限制。不要假設它一直記得所有規則。每次進入新階段前,都可以要求 Codex 動態重讀當下需要的檔案。例如準備改第一段前,只重讀 draft.md、style-guide.md 和 forbidden-phrases.md;進入審稿階段時,再重讀 draft.md、rewrite-checklist.md 和 forbidden-phrases.md。這樣做不是重複動作,而是把 context 重新放回 AI 面前。
開始下一輪前,請重新讀取本階段需要的規則。
請自行判斷這一輪需要讀取哪些 Markdown 檔案。
如果你不確定,先列出候選檔案和理由,不要改文。
現在不要改文。
請先用 5 點確認你這一輪會遵守的規則,然後等我確認。規則不需要一次塞滿,而是按階段載入:準備改寫時載入風格規則,準備審稿時載入 checklist,準備核對事實時才載入來源資料庫。AI 自主掃描檔案,人負責確認它選對 context,長任務中的遺忘風險才會被壓低。
Planning:先讓 AI 交改稿計畫,不要直接改正文
當 Codex 已經掃描 workspace,也確認了最小規則,下一步仍然不是「開始改」。你要先讓它交出改稿計畫。Planning 在 Harness Engineering 裡是一個 control point:AI 先說自己準備怎樣做,人確認方向後,它才可以動手。這個卡點可以防止 AI 一口氣把文章改成另一種文體,也可以讓你提早發現它誤解了讀者、語氣或保留資料。
在 Codex App 的輸入框貼這段 prompt:
請根據目前 workspace,先建立改稿計畫。
現在不要改寫正文,也不要修改任何檔案。
請輸出一個表格:
- 原稿段落或位置
- 主要問題
- 你打算怎樣改
- 必須保留的資訊
- 需要我確認的風險
最後請建議第一輪只改哪一小段。
列完後停下來,等我確認。好的回覆不應該只有「我會讓文章更自然」。它應該指出具體問題,例如開場太像廣告、某段有三段式排比、某句加入了原稿沒有的判斷,或者例子被抽象化。這時你可以在 Codex 回覆下方直接補充指令:
同意先改第 2 段。
但請保留原文中的例子,不要新增來源沒有的判斷。
請先只改這一段,改完後列出你刪掉或保留了甚麼。你把「改完整篇文章」拆成可審查的小任務,AI 負責提出操作路線,人負責批准路線。改稿失敗時,不要只叫它「再自然一點」,而是回到計畫表,看是哪一欄錯了:問題判斷錯、保留資訊錯、還是風險沒有先講清楚。
分段執行:人類掌舵,AI 每次只改一小段
確認改稿計畫後,才讓 Codex 開始改第一小段。這裡不要一次改全文。一次改全文看似快,但如果方向錯了,你要重看整篇,還要分辨哪些改動可留、哪些要退。分段執行在 Harness Engineering 裡是一個 feedback loop:AI 做一小步,人檢查結果,再決定繼續、修正規則或退回。
你可以用這段 prompt 開始第一輪:
請只改剛才確認的第一小段。
要求:
- 不要改其他段落
- 不要新增原稿沒有的事實
- 保留原文的具體例子
- 遵守 workspace 裡的風格規則和禁用句型
輸出格式:
1. 改寫後段落
2. 你刪掉了哪些 AI 味句型
3. 你保留了哪些原文資訊
4. 你不確定、需要我判斷的地方
完成後停下來,等我確認。讀者做完這一步,應該看到 Codex 只輸出一小段改寫結果,而不是整篇重寫。你要先對照原稿看三件事:事實有沒有被改、語氣有沒有貼近 style-guide.md、禁用句型有沒有被清掉。如果改得太像報告,就不要直接叫它重寫全文。你可以把問題轉成下一輪規則:
這一版太像中立報告。
請保留作者判斷,句子可以更直接。
把這條補進 rewrite-checklist.md:
- 改寫時不得把作者立場改成中立報告口吻。
補完後先回報你修改了 checklist 哪一條,不要繼續改正文。這就是「流程長出來」的實際做法。rewrite-checklist.md 不是開工前硬塞出來的文件,而是從 AI 犯過的錯、你做過的判斷、下一輪需要避免的問題裡長出來。人類掌舵不是每句都手改,而是在每個 control point 決定:這一版可以繼續、要改規則,還是要退回上一輪。
審稿清單:把「不要 AI 味」拆成可檢查的規則
跑過一兩輪分段改寫後,你會開始看到重複問題:AI 會把開場寫得太空泛,會用漂亮但沒有資料的金句收尾,會把作者立場磨平成中立報告,也可能為了讓句子順一點而加入原稿沒有的判斷。
這時才建立 rewrite-checklist.md。它不是另一份寫作守則,而是把已經發生過的錯誤固定下來,讓下一輪改稿有更清楚的驗收邊界。
你可以在 Codex App 的輸入框貼這段 prompt,讓 Codex 根據前幾輪問題先起草 checklist:
請根據目前改稿過程中出現過的問題,建立 rewrite-checklist.md。
要求:
- 只寫可檢查的規則
- 每條規則都要能用來審稿
- 不要寫抽象口號
- 不要改 draft.md
請先輸出你準備寫入 rewrite-checklist.md 的條目,等我確認後才建立或修改檔案。一份初版 rewrite-checklist.md 可以長這樣:
# rewrite-checklist.md
- 開場必須直接指出讀者正在做的具體動作,不用空泛背景句。
- 不得新增原稿或來源沒有的事實、數字、判斷。
- 不得把作者立場改成中立報告口吻。
- 刪除三段式排比,除非每一項都有具體例子。
- 刪除沒有操作、檔案、介面、來源或例子的抽象金句。
- 改寫後要列出:保留了甚麼、刪掉了甚麼、哪些地方需要人判斷。加入 checklist 後,改稿不再依賴「你覺得自然嗎」這種模糊感覺。Codex 每次輸出後,都要把結果放回清單檢查;人也不用從零開始讀整段,只要看它有沒有改動事實、有沒有保留例子、有沒有又滑回 AI 腔。這種驗收方式把錯誤擴散截斷在每一小段裡,下一輪輸出也更容易比較。
你可以用這段 prompt 叫 Codex 自查剛才改過的一段:
請用 rewrite-checklist.md 檢查剛才的改寫段落。
請輸出表格:
- checklist 條目
- 是否通過
- 具體證據
- 如果未通過,建議怎樣改
現在不要重寫段落。
先完成檢查,等我確認。這裡不要把 checklist 寫成「請寫得自然、有溫度、有深度」。這些詞不能檢查,也不能讓 AI 知道下一步要改哪裡。清單要像驗收口徑:有沒有新增事實、是否刪掉空泛開場、是否保留例子、是否列出需要人判斷的地方。規則越能落到句子和段落,AI 的自由度越不會變成亂改。
多版本與 Templates:流程穩定後才放大
單段改寫和 checklist 能穩定運作後,才值得把流程放大。
當一篇文章已經跑過掃描 workspace、planning、分段改寫、checklist 自查,你可以把流程放大。這時可以要求 Codex 產生兩個版本:一個保留原文結構,只做減法;另一個重排段落,讓讀者更快進入操作。多版本不是為了炫技,而是讓同一套規則在受控範圍內探索不同寫法,人只需要比較哪一版更貼近文章目的。
可以貼這段 prompt:
請根據已確認的規則,為剛才那一小段產生兩個版本。
版本 A:
- 保留原文段落結構
- 只做減法和語氣拉直
版本 B:
- 可以重排句子順序
- 但不得新增原稿沒有的資料
兩個版本都要遵守 workspace 裡的風格規則、禁用句型和 rewrite-checklist.md。
完成後請用 5 點比較兩個版本的取捨,然後停下來等我確認。如果這套流程連續用在幾篇文章都穩定,就可以把重複 prompt 抽成 templates。這一步不需要很複雜,只要把常用指令存成 Markdown 檔案,例如:
harness-engineering-article/
templates/
scan-workspace-template.md
rewrite-plan-template.md
segment-rewrite-template.md
checklist-review-template.md
context-load-template.md模板的價值不是節省幾行打字,而是把已經驗證過的工作路徑固定下來。下次改另一篇文章時,你不用重新發明流程,只要把新原稿放進 draft.md,再叫 Codex 讀取對應 template。AI 的工作入口被固定,人類確認點也保留下來,新的改稿任務就不會退回「貼全文、求自然」的狀態。
如果這套 template 已經很穩定,下一步才考慮把它整理成 Codex skill。skill 可以把一組固定流程、檔案檢查、prompt 寫法和 HITL 停頓包成可重用能力。你之後不需要每次都複製 template,只要在對話中呼叫對應 skill,Codex 就知道要先掃描 workspace、提出改稿計畫、分段改寫、用 checklist 自查,再停下來等你確認。這時候 workflow 不再只是幾個檔案,而是變成 Codex 可以反覆執行的工作習慣。
初學者不需要一開始就做 skill。先用 Markdown template 跑幾篇文章,確認流程真的穩定,再把它升級成 skill。太早封裝會把還沒驗證的壞流程固定下來;等 checklist、planning prompt 和 context reload prompt 都經過幾輪修改後,封裝才會減少重工,而不是放大錯誤。
你可以用這段 prompt 讓 Codex 先整理 template,而不是自己手動搬運:
請根據目前已確認有效的改稿流程,整理 templates 資料夾的建議檔案。
現在不要建立檔案。
請先列出:
- template 檔名
- 使用時機
- template 內應包含的 prompt
- 哪些地方必須留給人手動確認
列完後停下來,等我確認。流程放大時最容易出錯的地方,是把「AI 能自己做更多」誤解成「人可以退出」。更合理的做法,是把 AI 的自主權放在已經驗證過的格子裡:它可以掃描檔案、提出計畫、生成版本、用 checklist 自查;人仍然決定規則是否成立、版本是否採用、哪些判斷不能被改寫。這樣的工具流程才沒有離開文章主題:Harness Engineering 的落地,不是讓 AI 完全自由,而是讓自由發生在可被追蹤、可被驗收、可被修正的工作環境裡。
閉環更新:讓規則、Templates 和 Skill 越用越準
封裝不是終點。每次 Codex 改稿失手,你都要判斷問題應該回到哪一層:如果只是常見句型漏網,就補進 forbidden-phrases.md;如果是審稿口徑不清,就改 rewrite-checklist.md;如果是流程順序錯,例如太早改文、太遲重讀 context,就更新 template 或 skill。這個回流動作把一次失敗變成下一輪的約束,工具才不會反覆犯同一種錯。
閉環的好處有三個。
第一,舊錯誤不會被自動化;沒有回流,skill 只是把未成熟流程包起來,之後每次都更快地犯同一個錯。
第二,規則會貼近你的文章類型;寫產品教學、觀點文、人物稿,需要防的 AI 腔不完全一樣,checklist 要跟著場景調整。
第三,驗收會越來越省力;當常見錯誤已經寫進規則,人只需要看少數需要判斷的地方,而不是每次從頭審完整篇。
你可以在每次改稿結束後,用這段 prompt 做閉環整理:
請根據這一輪改稿結果,整理需要回流更新的規則。
請輸出表格:
- 發現的問題
- 問題應回流到哪個檔案或 skill
- 建議新增或修改的規則
- 這條規則下次可以防止甚麼錯誤
現在不要修改檔案。
先列出建議,等我確認。等你確認後,再讓 Codex 寫入對應檔案:
同意更新。
請只修改剛才確認的規則檔或 skill 內容。
修改後請回報:
1. 改了哪個檔案
2. 新增或修改了哪幾條規則
3. 下次流程中應在哪個階段讀取這些規則這個動作會把 harness 從「固定流程」推進到「會學習的流程」。AI 不只完成當下改稿,也把人類判斷轉成下一次可重用的上下文、護欄和驗收口徑。
結語:別再把 AI 工作留在一次性 prompt 裡
如果你的 AI 改稿流程仍然靠一段長 prompt 撐住,遺忘、漂移和難驗收會反覆出現。先用 Codex App 建一個最小 workspace,把原稿、語氣規則和禁用句型放在同一個可讀範圍內,再讓 AI 掃描、planning、分段改寫和停下來等人確認。
當錯誤開始重複,就把它寫進 checklist;當流程開始穩定,就抽成 templates;當 templates 已經跑過幾篇文章,再考慮封裝成 skill。封裝後仍要定期把失敗案例回流到 Markdown 規則或 skill 指令裡。Harness Engineering 的價值不在把流程做得很大,而是讓 AI 每一次多做一點時,人仍然看得見上下文、控得住邊界、驗得出結果,並且能把下一次做得更準。


