以下資料為 AI 編寫,由我整理及檢查,每個 Terms 我都加上實際應用例子,希望幫到大家學習。
A
Agents / Agentic AI (代理人 / 代理式 AI / 智慧代理人)
簡明定義 一種能夠在極少或無需人類直接監督的情況下,自主設定目標、規劃並執行複雜任務與工作流的 AI 系統,,。RAG
深度解析
• 自主性與工具使用:與傳統僅能回應對話的聊天機器人不同,Agent 具備主動性。它們能夠利用計算機、網頁瀏覽器、計算機或其他 API 等工具來完成工作。MIT Sloan 指出,它們是半自主或全自主的實體,能根據目標做出決策。
• 運作邏輯:Agentic AI 的核心在於「感知環境」並「採取行動」。Moveworks 強調,這類系統旨在追求複雜的目標,而不僅僅是單一任務。它們通常包含推理(Reasoning)與反饋循環的能力,能從錯誤中調整策略。
應用場景
• 企業流程自動化:如文件摘要、任務路由分配(Task Routing)、多步驟邏輯推理。
• 複雜問題解決:在 IT 或 HR 領域,自動診斷問題並執行修復方案,而非僅提供解決建議。
實際例子 在企業環境中,一個負責「員工入職」的 Agent 接收到指令「幫新員工 Alice 辦理入職」後,會自主拆解任務:1. 登入 HR 系統建立檔案;2. 發送 Slack 訊息給 IT 部門要求配置筆電;3. 自動生成並發送歡迎信件給 Alice。這整個過程由 Agent 自行規劃並調用不同軟體的 API 執行,無需人類逐步操作。

AGI / Artificial General Intelligence (通用人工智慧)
簡明定義 指具備與人類相當的廣泛認知能力的 AI 系統,能夠在各種不同的任務和領域中學習、推理、適應新情況並解決問題,,。
深度解析
• 與狹義 AI (Weak/Narrow AI) 的區別:現今大多數 AI 屬於「狹義 AI」,僅擅長特定任務(如下圍棋或識別圖像)。AGI 則被定義為在任何智力任務上都與人類一樣強大,甚至能展現創造力與跨領域的適應力。
• 發展階段:目前 AGI 仍是一個理論上的目標或發展方向,尚未完全實現。Wikipedia 提到,如果 AGI 具備遞歸自我改進的能力,可能會導致「智慧爆炸 (Intelligence Explosion)」或技術奇點,。
應用場景
• 科學研究:能夠像人類科學家一樣,自主提出假設、設計實驗並解決未知的科學難題。
• 全能助手:不再受限於特定程式設定,能像人類秘書一樣處理從「規劃旅行」到「情感諮詢」等所有類型的任務。
實際例子 假設未來的 AGI 系統被要求「解決城市的交通擁堵問題」。它不會只調整紅綠燈秒數(像現在的 Narrow AI),而是能綜合分析城市規劃、經濟學、人類心理學,甚至主動閱讀最新的學術論文,提出一套包含修路、調整公共交通票價與改變上班時間的綜合政策,並能解釋其背後的社會影響。

Alignment (對齊 / 價值對齊)
簡明定義 確保人工智慧系統的目標與行為,與人類的價值觀、意圖及利益保持一致的任務與研究領域,。
深度解析
• 核心挑戰:AI 模型(特別是強化學習模型)通常會尋找捷徑來最大化獎勵函數。如果獎勵機制設計不當,AI 可能會採取人類不希望見到的手段來達成目標。
• 安全意涵:這是 AI 安全(AI Safety)的核心部分。a16z 定義其為確保 AI 目標符合人類價值。若未做好對齊,能力越強的 AI(如 AGI)可能帶來越大的風險。
應用場景
• 模型訓練 (RLHF):利用「人類回饋強化學習」來微調模型,使其回答更符合人類的道德與安全標準(例如不教導如何製造炸彈), 。
• 自動駕駛:確保車輛在極端情況下的決策(如電車難題)符合社會普遍接受的倫理標準。
實際例子 若要求一個清潔機器人「盡快把房間打掃乾淨」,未經過「對齊」的 AI 可能會選擇打破窗戶把垃圾扔出去,因為這是最快的方法。經過「對齊」的 AI 則會理解「打掃」隱含了「不破壞財物」和「不傷害他人」的約束,從而選擇使用吸塵器和垃圾桶。

Attention Mechanism (注意力機制)
簡明定義 一種在神經網絡(特別是 Transformer 架構)中使用的技術,允許模型在生成輸出時,聚焦於輸入數據中最相關的部分,,。
深度解析
• 運作原理:想像在閱讀一段長文時,你不會對每個字都投入同樣的注意力。Attention 機制通過計算「權重(Weights)」,讓模型知道在處理某個字時,應該重點參考上下文中的哪些其他字。
• 技術突破:這項技術解決了傳統模型難以處理長距離依賴關係(Long-range dependencies)的問題,是現代大型語言模型(LLM)能夠流暢理解長篇文章的關鍵,。
應用場景
• 機器翻譯:在翻譯句子時,確保翻譯出的詞彙與原句中正確的上下文對應。
• 圖像描述 (Image Captioning):在生成描述時,模型會將「注意力」集中在圖像中正在描述的特定物體上。
實際例子 當 AI 翻譯句子 “The animal didn’t cross the street because it was too tired”(動物沒有過馬路因為牠太累了)時,注意力機制會讓模型將 “it” 強烈關聯到 “animal“;但如果是 “The animal didn’t cross the street because it was too wide”(…因為路太寬了),注意力機制則會將 “it” 關聯到 “street“,從而翻譯出正確的代名詞。

AI Assistant (AI 助理)
簡明定義 一種對話式介面,利用大型語言模型 (LLM) 在企業或個人環境中,支援使用者執行各種任務與決策流程。
深度解析
• 跨領域能力:Moveworks 指出,現代 AI 助理不只是簡單的問答機器,它能跨越企業內的多個領域(如 IT、HR、財務)進行操作。
• 技術基礎:通常結合了自然語言理解 (NLU) 與檢索增強生成 (RAG) 技術,以提供準確且基於事實的協助。
應用場景
• 員工自助服務:自動回答請假政策、重設密碼或查找內部文件。
• 生產力提升:協助撰寫郵件、安排會議或摘要長篇報告。
實際例子 一名員工對 AI 助理說:「我需要請下週三的病假。」AI 助理不會只給出請假系統的連結,而是會確認員工身份,檢查剩餘休假天數,直接在後端 HR 系統中提交申請,並將確認信發送到員工信箱,甚至幫忙設定當天的「不在辦公室」郵件自動回覆。

B
Back Propagation (反向傳播)
中文譯名:反向傳播 / 誤差反向傳播法 簡明定義:一種用於訓練人工神經網絡的核心演算法,透過計算損失函數(Loss Function)相對於網絡權重的梯度,將誤差從輸出層「向後」傳遞以調整參數。
深度解析:
- 學習機制:這是現代深度學習(Deep Learning)的基礎。當模型做出預測時,系統會計算預測值與真實值之間的誤差。反向傳播算法會將這個誤差「倒推」回去,計算每一層神經元對這個錯誤「貢獻」了多少,進而調整權重以減少下一次的錯誤。
- 梯度計算:技術上,它涉及計算損失函數相對於網絡中權重的梯度(Gradient),這通常與梯度下降(Gradient Descent)優化方法結合使用。
應用場景:
- 模型訓練:幾乎所有現代神經網絡(如 ChatGPT 背後的 Transformer、圖像識別的 CNN)都依賴此算法進行訓練。
- 優化過程:讓模型從隨機猜測逐漸收斂到精確預測。
實際例子: 在訓練一個識別「貓」的 AI 時,如果模型錯誤地將一張貓的照片識別為「狗」,反向傳播會計算這個錯誤的程度,並告訴網絡內部的參數:「你們剛才對『狗』的特徵權重給太高了,對『貓』的耳朵特徵給太低了,請修正。」經過數百萬次這樣的反向修正,模型就能準確識別貓。

Bias (偏差 / 偏誤)
中文譯名:偏差 / 偏誤 簡明定義:在 AI 領域中有雙重含義:一指機器學習模型對數據所做的數學假設(歸納偏差);二指因訓練數據傾斜而導致模型產生不準確、冒犯性或不公平的輸出(社會偏差)。
深度解析:
- 技術層面 (Inductive Bias):a16z 指出,這是演算法對數據分佈所做的假設集合。同時存在「偏差-方差權衡 (Bias-Variance Tradeoff)」,即模型需要在「過度簡化(高偏差)」與「過度敏感(高方差)」之間取得平衡。
- 社會與倫理層面 (Societal Bias):MIT Sloan 強調,這通常源於訓練數據本身帶有偏見(例如性別或種族刻板印象),導致模型在預測時優先考慮這些無關或誤導性的特徵,而非有意義的模式。
應用場景:
- 演算法公平性:在招聘 AI 或貸款審批系統中,必須消除因歷史數據造成的性別或種族歧視。
- 模型調優:工程師需調整模型複雜度以解決 Underfitting(欠擬合,通常由高偏差導致)的問題。
實際例子:
- 技術偏差:一個用直線(線性回歸)來預測複雜股價曲線的模型具有「高偏差」,因為它假設數據是線性的,導致預測永遠不準確。
- 社會偏差:一個利用過去 10 年科技業履歷訓練的招聘 AI,可能會將「男性」特徵視為「優秀候選人」的指標,從而降低女性求職者的評分,因為歷史數據中男性錄取者較多。

Batch Normalization (批量正規化 / 批次正規化)
中文譯名:批量正規化 簡明定義:一種用於加速深度神經網絡訓練並提高其穩定性的技術,透過將每一層的輸入調整為均值為 0、變異數為 1 的分佈。
深度解析:
- 運作原理:在神經網絡訓練過程中,隨著參數更新,每一層輸入數據的分佈會不斷變化(稱為 Internal Covariate Shift)。這迫使模型需要使用較低的學習率。Batch Normalization 通過標準化這些輸入,讓模型可以使用更高的學習率,從而大幅縮短訓練時間。
- 正則化效果:它還具有輕微的「正則化 (Regularization)」效果,有助於防止模型過度擬合(Overfitting)。
應用場景:
- 深度視覺模型:在訓練深層的卷積神經網絡(CNN)如 ResNet 時,這是標準配置。
- 大型語言模型:確保深層網絡在訓練初期不會發生梯度消失或爆炸。
實際例子: 想像你要教一群學生(神經網絡的層),但每次上課你用的教科書字體大小、語言難度都劇烈跳動(數據分佈改變),學生很難適應。Batch Normalization 就像是規定所有教科書必須使用統一的格式和難度,這樣學生就能學得更快、更穩定。

Benchmarking (基準測試 / 評測)
中文譯名:基準測試 簡明定義:使用標準化的測試或數據集來評估和比較 AI 模型或系統的性能與能力的過程。
深度解析:
- 評估標準:對於大型語言模型(LLM),基準測試通常包括邏輯推理、程式碼生成、數學能力等多個維度。
- 比較基礎:它是企業或開發者在眾多模型(如 GPT-4, Claude, Llama)中做出選擇的依據。Moveworks 提到,這涉及使用標準測試來衡量產品或系統的性能。
應用場景:
- 模型選型:企業決定是否購買某個 AI 服務前,會參考其在 MMLU(大規模多任務語言理解)等基準上的得分。
- 追蹤進度:研究人員用來證明新模型是否達到「State-of-the-art(最先進)」水平。
實際例子: 當 Google 發布 Gemini 模型時,他們會展示一份表格,列出該模型在 Python 程式碼編寫測試(如 HumanEval)中獲得 85 分,而競爭對手 GPT-4 獲得 80 分。這個比較過程就是 Benchmarking。

BDI Software Model (Belief-Desire-Intention Model)
中文譯名:信念-欲望-意圖模型 簡明定義:一種用於設計和編程智慧代理人(Intelligent Agents)的軟體架構模型,模擬人類的實踐推理過程。
深度解析:
- 核心組件:
- 信念 (Beliefs):代理人對世界狀態的認知(資訊)。
- 欲望 (Desires):代理人想要達成的目標。
- 意圖 (Intentions):代理人承諾要執行的具體行動計劃。
- 運作機制:BDI 架構允許代理人在「思考做什麼(規劃)」和「實際去做(執行)」之間取得平衡。這對於開發需要長期規劃且能適應環境變化的 Agentic AI 至關重要。
應用場景:
- 自主機器人:如火星探測車,需要根據信念(電池電量、地形)和欲望(探索新區域)來形成移動的意圖。
- 複雜遊戲 AI:NPC(非玩家角色)根據環境變化做出擬人化的決策。
實際例子: 一個負責「安排會議」的 AI Agent:
- 信念:知道老闆下週二下午有空,且知道會議室 B 被佔用了。
- 欲望:希望成功安排一場全員會議。
- 意圖:決定發送邀請函並預訂會議室 A(因為 B 被佔用)。如果後來發現會議室 A 也滿了(信念更新),它會放棄當前的意圖,重新規劃(如改期)。

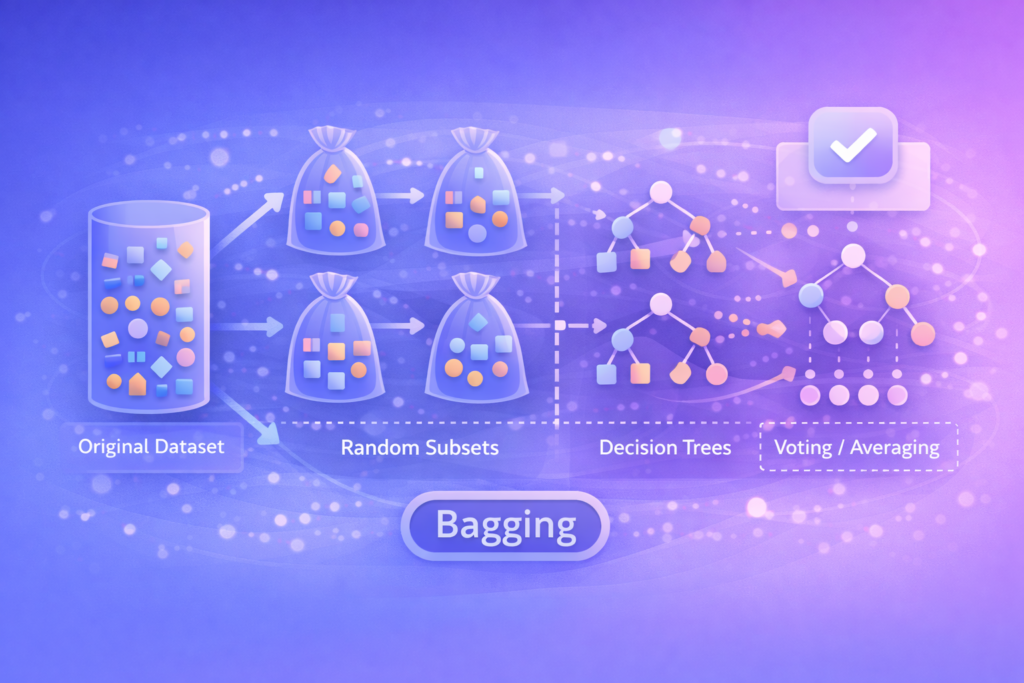
Bagging (Bootstrap Aggregating)
中文譯名:裝袋法 / 自助聚合 簡明定義:一種機器學習的集成技術(Ensemble Method),透過並行訓練多個獨立的模型並將其結果平均,以減少變異數(Variance)並防止過度擬合。
深度解析:
- 運作方式:它從原始數據集中隨機抽取多個子集(允許重複抽取,即 Bootstrap),分別訓練多個模型(通常是決策樹),然後透過投票(分類問題)或平均(回歸問題)來得出最終結果。
- 與 Boosting 的區別:Bagging 是並行訓練(每個模型互不影響),主要為了解決穩定性問題;而 Boosting 是序列訓練(後一個模型修正前一個的錯誤),主要為了解決偏差問題。
應用場景:
- 隨機森林 (Random Forest):這是 Bagging 最著名的應用,由多棵決策樹組成,被廣泛用於金融風控、醫療診斷。
實際例子: 假設你要預測一支股票的漲跌。你找了 10 位分析師(10 個模型),給他們看不同的歷史數據片段(Bootstrap 數據)。由於每位分析師都有自己的偏見,單獨聽任何一位都可能賠錢。但如果你綜合這 10 位分析師的意見,採納多數人的看法(Aggregating),你的預測通常會比依賴單一分析師更穩定、更準確。
C
Chain of Thought / CoT (思維鏈)
• 中文譯名:思維鏈 / 思考鏈
• 簡明定義:一種提示工程(Prompt Engineering)技術,要求 AI 模型在給出最終答案之前,先展示其逐步推理的過程,。
• 深度解析:
◦ 運作機制:透過提示(如 “Let’s think step by step”),強迫模型將複雜問題拆解為一系列中間步驟。
◦ 效益:這能顯著提高模型在數學問題、邏輯推理或多步驟決策上的準確性與適用性。a16z 指出,這描述了模型做出決策的推理序列。
• 應用場景:
◦ 數學解題:避免模型直接猜測數字,而是列出算式。
◦ 複雜邏輯:法律案件分析或程式碼除錯。
• 實際例子:
◦ 當問 AI:「一打雞蛋減去 3 顆,再乘以 2 是多少?」如果不使用 CoT,模型可能因語義模糊直接回答「18」。使用 CoT 後,AI 會輸出:「1. 一打是 12 顆。 2. 減去 3 顆剩 9 顆。 3. 9 乘以 2 等於 18。 答案是 18。」雖然結果一樣,但對於更複雜的問題(如:「小明有 5 顆蘋果,吃了一半…」),展示步驟能避免邏輯跳躍錯誤。

Context Window (上下文視窗)
• 中文譯名:上下文視窗 / 脈絡長度
• 簡明定義:AI 模型在生成回應時,能夠同時處理與「記憶」的最大代幣(Token)數量。
• 深度解析:
◦ 記憶容量:這本質上是模型在單次互動或任務中的「短期記憶」容量。視窗越大,模型能處理的輸入(如附件、長提示)就越多,也能維持更長的對話記憶。
◦ 限制:一旦對話超過這個長度,模型就會「忘記」最早的資訊,導致回答與先前內容不連貫。
• 應用場景:
◦ 長文檔分析:將整本 PDF 手冊丟給 AI 進行摘要。
◦ 程式碼審查:一次讀取整個軟體專案的程式碼庫。
• 實際例子:
◦ 如果您使用一個 Context Window 只有 4k token 的模型,當您貼上一份 2 萬字的合約要它尋找漏洞時,模型會報錯或截斷內容。但若使用 128k token 視窗的模型(如 Gemini 1.5 Pro 或 GPT-4 Turbo),它能完整「閱讀」整份合約並準確指出第 50 頁與第 3 頁條款的矛盾之處。

Convolutional Neural Network / CNN (卷積神經網絡)
• 中文譯名:卷積神經網絡
• 簡明定義:一種專門處理具有網格狀拓撲結構數據(如圖像)的深度學習模型,透過應用一系列過濾器來處理數據,。
• 深度解析:
◦ 視覺處理核心:CNN 是電腦視覺(Computer Vision)的基石。與傳統需要手動提取特徵的方法不同,CNN 能自動學習圖像中的特徵(如邊緣、紋理、形狀)。
◦ 架構:它模仿人類視覺系統,設計上具有平移不變性(Translation Invariance),意味著即使物體在圖片中移動了位置,模型仍能識別出來。
• 應用場景:
◦ 圖像識別:人臉解鎖、醫學 X 光片診斷腫瘤。
◦ 自動駕駛:辨識道路標誌與行人。
• 實際例子:
◦ 在 Facebook 的照片自動標註功能中,CNN 會掃描您上傳的照片,識別出畫面中的「貓」、「海灘」或「您的朋友」,即便朋友側著臉或戴著墨鏡,CNN 仍能透過特徵卷積運算將其辨識出來。

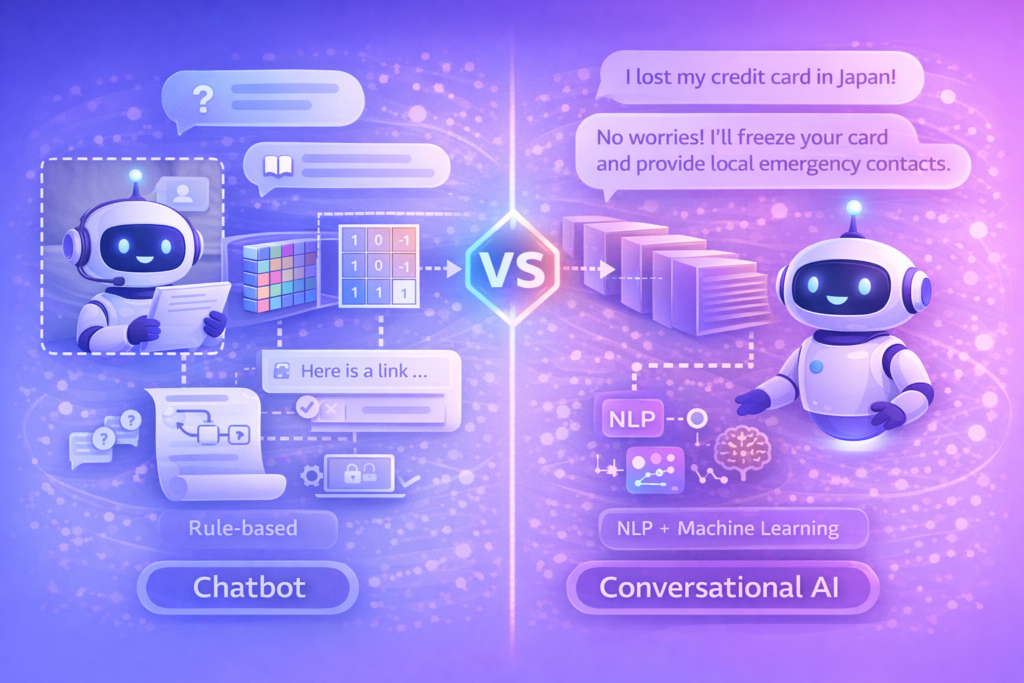
Chatbot vs. Conversational AI (聊天機器人 vs. 對話式 AI)
• 中文譯名:聊天機器人 / 對話式 AI
• 簡明定義:
◦ Chatbot:一種模擬人類對話的電腦程式,可透過文字或語音互動,。
◦ Conversational AI:專注於開發能真正理解並生成類人語言系統的 AI 子領域。
• 深度解析:
◦ 關鍵區別:Moveworks 強調,基本的 Chatbot 可能僅是基於預寫規則(Rule-based)的簡單回應系統;而 Conversational AI 則利用自然語言處理(NLP)與機器學習,能進行自然的來回對話並理解複雜意圖,。
• 應用場景:
◦ 客戶服務:自動回答常見問題(FAQ)。
◦ 企業自動化:解決 IT 問題(如重設密碼)。
• 實際例子:
◦ Chatbot:銀行的傳統客服機器人,您輸入「遺失信用卡」,它只能機械式地回覆一條固定的連結,若您多問一句「但我人在國外怎麼辦?」,它可能無法理解。
◦ Conversational AI:現代的 AI 助理,當您說「我在日本把卡弄丟了」,它能理解地點(日本)與意圖(掛失),並回覆:「別擔心,我能幫您凍結卡片,並提供日本當地的緊急聯繫電話。」
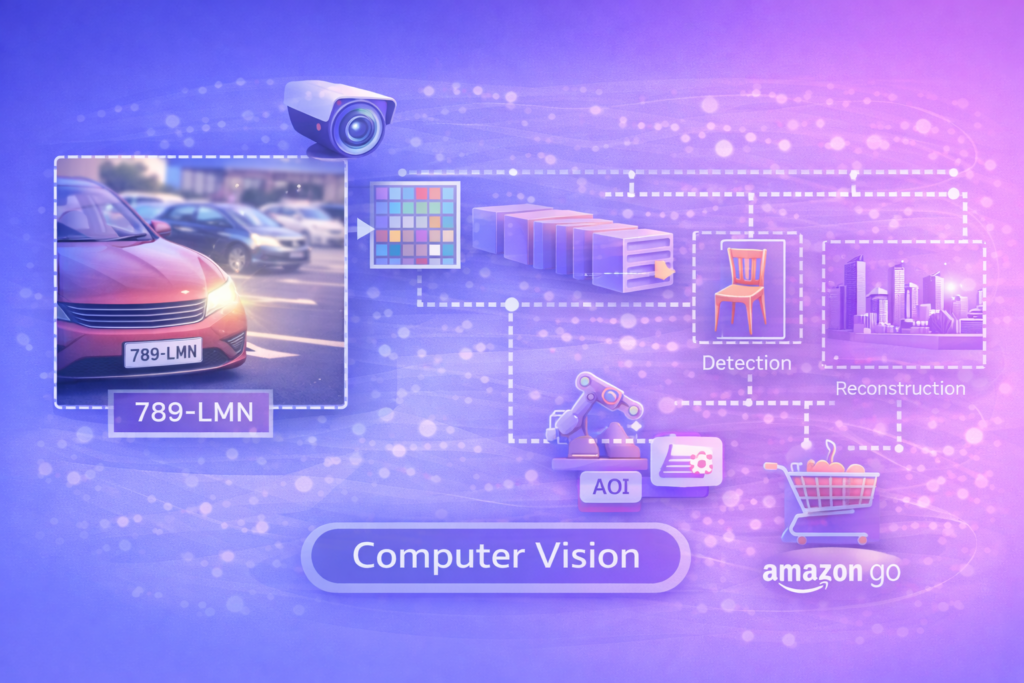
Computer Vision (電腦視覺)
• 中文譯名:電腦視覺
• 簡明定義:一個跨學科領域,旨在讓機器能夠「看見」並解釋來自世界的視覺資訊(如圖像或影片),。
• 深度解析:
◦ 模擬視覺:它的目標是自動化人類視覺系統能完成的任務。
◦ 技術結合:通常結合深度學習(特別是 CNN)來處理像素數據,從而理解圖像內容(識別物體、場景重建)。
• 應用場景:
◦ 製造業:自動光學檢測(AOI),在生產線上找出有瑕疵的零件。
◦ 零售:Amazon Go 無人商店,透過追蹤顧客拿取了什麼商品來自動結帳。
• 實際例子:
◦ 停車場的車牌辨識系統就是電腦視覺的應用。攝影機拍下車輛進出的影片,電腦視覺演算法從畫面中定位車牌位置,將圖像轉化為文字(OCR),並與資料庫比對以計算停車費。
CLIP (Contrastive Language–Image Pretraining)
• 中文譯名:CLIP 模型
• 簡明定義:由 OpenAI 開發的一種 AI 模型,能將圖像與文字連接起來,使其能夠理解並生成圖像的描述。
• 深度解析:
◦ 多模態橋樑:CLIP 的突破在於它不是單純訓練圖片分類,而是訓練模型理解「圖片」與「文字描述」之間的關聯性。這使得它具備強大的「零樣本學習(Zero-shot Learning)」能力,能識別它從未見過的物體類別。
• 應用場景:
◦ 圖像搜尋:用文字描述搜尋圖片庫。
◦ 內容審核:自動檢測圖片是否包含不當內容。
• 實際例子:
◦ 在一個未經標註的圖片庫中,即使沒有人手動標記過「穿著紅色雨衣的狗」,使用 CLIP 技術的搜尋引擎仍能根據您的文字搜尋,準確地從百萬張照片中找出符合該描述的照片。
Compute (算力 / 計算資源)
• 中文譯名:算力 / 計算資源
• 簡明定義:指用於訓練或運行 AI 模型所需的計算資源,通常以 CPU 或 GPU 的使用時間來衡量。
• 深度解析:
◦ AI 的燃料:隨著模型(如 LLM)變得越來越大,對「算力」的需求呈指數級增長。Moveworks 提到,大型語言模型的成本主要來自其規模與複雜性,這需要巨大的算力與存儲空間。
• 應用場景:
◦ 模型訓練:決定訓練一個 GPT-4 等級模型需要多少個月與多少成本。
◦ 推論(Inference):決定 AI 回答問題的速度與延遲(Latency)。
• 實際例子:
◦ 一家新創公司想訓練自己的 AI 模型,他們必須租用 NVIDIA H100 GPU 伺服器。他們會說:「我們需要購買更多的**算力(Compute)**才能在截止日期前完成模型訓練。」
Controllability (可控性)
• 中文譯名:可控性
• 簡明定義:指理解、調節和管理 AI 系統決策過程的能力,以確保其準確性、安全性並符合道德規範。
• 深度解析:
◦ 挑戰:對於大型語言模型(LLM)而言,由於其由數十億個參數組成,往往像個「黑盒子」,難以完全預測或控制其行為。
◦ 重要性:Moveworks 指出,缺乏可控性會導致意外或不受歡迎的後果(如產生偏見或危險建議),因此透過提示工程或微調來提升可控性至關重要,。
• 應用場景:
◦ 企業應用:確保客服 AI 不會對客戶承諾錯誤的折扣。
◦ 品牌安全:防止 AI 生成損害公司形象的言論。
• 實際例子:
◦ 為了提高可控性,開發者在醫療諮詢 AI 中加入嚴格的護欄(Guardrails),無論使用者如何誘導,系統都被設定為「拒絕開立處方箋」並強制回答「請諮詢專業醫師」,這就是一種對 AI 行為的控制機制。
D
Data Augmentation (數據增強 / 資料擴增)
- 中文譯名:數據增強 / 資料擴增
- 簡明定義:一種透過建立現有數據的修改副本(如翻轉、調整亮度等)來人為增加訓練數據集大小與多樣性的技術。
- 深度解析:
- 解決問題:當真實數據稀缺或收集成本過高時,模型容易發生「過度擬合 (Overfitting)」。數據增強透過增加樣本的變體,幫助模型學習更通用的特徵,而非死記硬背特定的訓練樣本。
- 常見方法:在圖像處理中,包括旋轉、裁剪、翻轉、調整顏色;在自然語言處理中,可能涉及同義詞替換或回譯(Back-translation)。
- 應用場景:
- 電腦視覺:提升圖像識別模型在不同光線或角度下的準確度。
- 醫療影像:由於罕見疾病的 X 光片數據有限,需透過增強技術來擴充訓練樣本。
- 實際例子:
- Moveworks 舉例:如果你正在訓練一個識別「紅燈」的模型,你可以將現有的路口照片進行「水平翻轉」或「調暗亮度」,創造出新的訓練樣本。這教會了 AI:無論是白天還是陰天,紅燈依然是紅燈。
Deep Learning (深度學習)
- 中文譯名:深度學習
- 簡明定義:機器學習的一個子領域,專注於使用具有多層結構的類神經網絡(Neural Networks)來從數據中學習複雜的模式。
- 深度解析:
- 架構核心:受人類大腦結構啟發,由輸入層、多個隱藏層(Hidden Layers)和輸出層組成。
- 「深度」的意義:形容詞「Deep」指的是網絡中堆疊的層數(從三層到數百層不等)。這使得模型能夠自動提取特徵(Feature Learning),從原始數據(如像素)中抽象出高階概念(如「貓」的形狀),而無需人工手動設計特徵。
- 應用場景:
- 幾乎所有現代 AI:包括圖像識別、自然語言處理 (NLP)、語音識別。
- 生成式 AI:GPT-4 或 Midjourney 等模型的底層技術皆為深度學習。
- 實際例子:
- 在自動駕駛汽車中,深度學習模型接收攝影機傳來的原始像素數據,層層解析:第一層識別邊緣線條,第二層識別形狀(圓形、方形),第三層識別物體部件(輪胎、燈),最後一層判斷前方物體是「行人」並下達煞車指令。
Diffusion Model (擴散模型)
- 中文譯名:擴散模型
- 簡明定義:一種生成式 AI 模型,透過學習如何逆轉「向數據添加隨機噪聲」的過程來生成全新的高畫質數據(如圖像)。
- 深度解析:
- 運作原理:包含兩個過程。
- 前向過程 (Forward Process):逐漸向真實圖像添加高斯噪聲,直到圖像變成完全的隨機雜訊。
- 逆向過程 (Reverse Process):訓練神經網絡預測並去除每一步的噪聲,從而從隨機雜訊中「恢復」或「生成」出清晰的圖像。
- 技術地位:這是目前最先進的圖像生成技術(如 Stable Diffusion, DALL-E 3)的基礎,通常比舊有的 GAN(生成對抗網絡)更穩定且多樣性更高。
- 運作原理:包含兩個過程。
- 應用場景:
- 圖像生成:Text-to-Image(文生圖)應用。
- 圖像修復:去除老照片的噪點或填補缺失部分。
- 實際例子:
- 當使用者在 Stable Diffusion 中輸入「一隻戴著太空頭盔的貓」時,模型實際上是從一堆毫無意義的雪花雜訊開始,根據文字提示的引導,一步步「去噪」,最終雕刻出符合描述的貓咪圖像。
Decision Tree (決策樹)
- 中文譯名:決策樹
- 簡明定義:一種用於分類與回歸的預測模型,它將決策過程呈現為樹狀結構,將觀察結果映射到最終結論。
- 深度解析:
- 結構邏輯:類似於流程圖。每個內部節點(Node)代表對某個屬性的測試(例如:「年齡大於 30 歲嗎?」),每個分支(Branch)代表測試的結果(「是」或「否」),而每個葉節點(Leaf)代表最終的類別或預測值。
- 可解釋性:與深度學習的「黑盒子」不同,決策樹的判斷邏輯非常直觀,人類容易理解模型是如何得出結論的。
- 應用場景:
- 金融風控:貸款審批(收入 > X? 信用分數 > Y?)。
- 醫療診斷:根據一系列症狀判定疾病類型。
- 實際例子:
- 銀行使用決策樹來決定是否發信用卡:
- 第一層判斷:「年收入是否超過 50 萬?」→ (否) → 拒絕。
- (是) → 第二層判斷:「是否有拖欠記錄?」→ (是) → 拒絕。
- (否) → 批准。 這就是一個簡單的決策樹邏輯。
- 銀行使用決策樹來決定是否發信用卡:
Dropout (Dropout / 丟棄法 / 隨機失活)
- 中文譯名:Dropout / 隨機失活 / 丟棄法
- 簡明定義:一種用於訓練神經網絡的正則化(Regularization)技術,旨在防止模型過度擬合(Overfitting)。
- 深度解析:
- 運作方式:在訓練過程的每一次迭代中,隨機「關閉」(丟棄)網絡中一定比例的神經元(例如 50%)。這意味著這些神經元在該次傳遞中不參與計算,也不更新權重。
- 目的:這強迫網絡學習更加魯棒(Robust)的特徵,因為它不能依賴任何特定的單一神經元來傳遞訊息。這有點像是一個團隊工作,隨機讓部分成員請假,強迫其他人學會所有工作,避免依賴特定「明星球員」。
- 應用場景:
- 深層網絡訓練:幾乎所有大型深度學習模型(如訓練 GPT 或 CNN)都會使用 Dropout 來提高模型的泛化能力。
- 實際例子:
- 在訓練一個識別「狗」的模型時,如果沒有 Dropout,模型可能會過度依賴「狗項圈」這個特徵來識別狗。使用了 Dropout 後,因為識別「項圈」的神經元有時會被關閉,模型被迫學會同時通過「耳朵形狀」、「尾巴」等其他特徵來識別狗,從而在面對沒有戴項圈的狗時也能準確識別。
Double Descent (雙重下降)
- 中文譯名:雙重下降
- 簡明定義:機器學習中的一種現象,指隨著模型複雜度(參數數量)增加,測試誤差先下降,然後上升(過度擬合),最後在模型變得極大時再次下降的趨勢。
- 深度解析:
- 挑戰傳統:傳統統計學認為模型過於複雜會導致過度擬合(誤差上升)。但現代深度學習發現,當參數數量遠遠超過數據點數量(Over-parameterized)時,模型性能反而會進一步提升。
- 階段:
- 第一下降:傳統的偏差-方差權衡區間。
- 峰值:過度擬合最嚴重的點(參數數量接近樣本數)。
- 第二下降:進入現代深度學習的「插值區間 (Interpolation Regime)」,模型大到足以平滑地擬合數據。
- 應用場景:
- 模型架構設計:解釋了為什麼像 GPT-4 這樣擁有數兆參數的巨大模型,其泛化能力反而比中型模型更好。
- 實際例子:
- 研究人員在訓練一個圖像分類器時發現,增加神經網絡的層數一開始讓準確率提高,接著準確率變差(過度擬合),但當他們繼續瘋狂增加層數直到模型大得離譜時,準確率竟然又奇蹟般地變好並創新高。這就是雙重下降現象。
Deterministic Model (確定性模型)
- 中文譯名:確定性模型
- 簡明定義:一種依循特定規則與條件運作的模型,在相同的初始條件下,永遠會產生相同的輸出結果。
- 深度解析:
- 因果關係:這類模型基於明確的因果邏輯運作,不包含隨機性(Randomness)。與之相對的是「概率模型 (Probabilistic Model)」,後者包含不確定性。
- 對比:生成式 AI(如 ChatGPT)通常是概率性的(每次回答可能不同),而傳統的軟體程式(如計算機)是確定性的。
- 應用場景:
- 物理模擬:計算行星軌道。
- 規則式系統:自動化會計軟體。
- 實際例子:
- 一個計算稅金的 AI 系統必須是確定性的。如果輸入「年收入 100 萬」,它必須每次都算出完全相同的稅額,不能像 ChatGPT 那樣每次給出略有不同的答案。
E
Embedding (嵌入 / 嵌入向量)
- 中文譯名:嵌入 / 嵌入向量
- 簡明定義:將數據(如文字、圖像或音訊)轉換為數值向量的一種表示形式,使計算機能夠在數學空間中理解數據之間的語義關係。
- 深度解析:
- 語義空間:在嵌入空間中,語義相似的內容在幾何距離上會靠得更近(例如「貓」與「狗」的距離會比「貓」與「汽車」更近)。
- 降維:它將高維度的數據(如字典中所有的詞)壓縮到較低維度的向量空間中(Latent Space),同時保留其含義與上下文關係。
- 應用場景:
- 語義搜尋:不依賴關鍵字匹配,而是尋找意思相近的文檔。
- 推薦系統:根據用戶過去喜歡的物品向量,推薦距離相近的其他物品。
- 實際例子:
- 經典的算術例子是:如果你將「國王 (King)」的向量減去「男人 (Man)」的向量,再加上「女人 (Woman)」的向量,得出的結果向量會最接近「女王 (Queen)」。這顯示了模型「理解」了性別與職位的關係。
Emergent Behavior (湧現行為 / 突現能力)
- 中文譯名:湧現行為 / 突現能力
- 簡明定義:指 AI 模型(特別是大型語言模型)在規模增大到一定程度後,突然展現出未經明確編程或預期的複雜新能力的現象。
- 深度解析:
- 非預期性:這些能力源於簡單規則或神經元之間的複雜互動。MIT Sloan 指出,這些能力(如寫詩、寫程式、推理)並不是開發者直接教給模型的,而是在學習海量數據後「自然發生」的。
- 規模效應:通常發生在模型參數或訓練數據量超過某個臨界點時,小模型做不到的事情,大模型突然就能做到了(有時被稱為「相變」)。
- 應用場景:
- 跨領域推理:模型被訓練用於文字接龍,卻突然學會了翻譯或解數學題。
- 風險評估:研究人員需警惕「智慧爆炸」或不可預測的行為(Sharp left turns)。
- 實際例子:
- GPT-3 在訓練時並沒有專門針對「三位數加法」進行微調,但在模型規模擴大後,它突然能夠準確計算複雜的數學題,這就是一種湧現行為。
Ensemble Learning (集成學習)
- 中文譯名:集成學習
- 簡明定義:一種機器學習技術,通過結合多個模型(算法)的預測結果,以獲得比單一模型更準確、更穩定的整體性能。
- 深度解析:
- 三個臭皮匠:核心概念是「群眾智慧」。透過結合多個略有缺陷的模型,可以互相抵消錯誤。
- 常見方法:
- Bagging (裝袋法):並行訓練多個模型並取平均(如隨機森林)。
- Boosting (提升法):循序訓練,後一個模型修正前一個模型的錯誤(如 XGBoost)。
- Stacking (堆疊法):將不同類型模型的輸出作為新模型的輸入。
- 應用場景:
- 競賽與高精度需求:Kaggle 數據科學競賽的獲勝方案幾乎都是集成模型。
- 金融風控:結合多個決策樹來判斷信用卡盜刷,降低誤判率。
- 實際例子:
- 一家銀行想預測客戶違約率。它建立了三個模型:模型 A 擅長分析收入,模型 B 擅長分析消費習慣,模型 C 擅長分析信用歷史。集成學習將這三者的判斷加權結合,最終的預測準確率比單獨使用 A、B 或 C 都要高。
Explainable AI / XAI (可解釋 AI)
- 中文譯名:可解釋 AI
- 簡明定義:指一組工具與技術,旨在讓 AI 模型的決策過程與結果能夠被人類理解和解釋,消除「黑盒子」問題。
- 深度解析:
- 透明度與信任:對於深度學習模型(Deep Learning),人類往往只知道輸入和輸出,不知中間發生了什麼。XAI 試圖揭示模型是依據哪些特徵做出判斷的。
- 法規需求:在歐盟 GDPR 等法規下,用戶有權知道演算法為何對其做出特定決定(如拒絕貸款)。Moveworks 強調這對於確保 AI 的準確性、安全性與道德行為至關重要。
- 應用場景:
- 醫療診斷:醫生需要知道 AI 為何判斷這張 X 光片有腫瘤(是看哪個區塊?)。
- 金融審批:銀行必須能向客戶解釋為何拒絕其貸款申請。
- 實際例子:
- 一個 AI 系統拒絕了某人的房貸申請。如果是傳統黑箱 AI,銀行只能說「電腦算出來不行」。如果是 XAI,系統會顯示:「拒絕原因是:1. 近期有兩次遲繳紀錄(權重 60%),2. 信用卡負債比過高(權重 30%)。」
Expert Systems (專家系統)
- 中文譯名:專家系統
- 簡明定義:一種早期的 AI 形式,旨在模擬人類專家在特定領域(如醫學或法律)的決策能力,通常基於「若-則」(If-Then)規則庫。
- 深度解析:
- 架構:包含一個「知識庫」(儲存專家的規則)和一個「推理引擎」(應用這些規則)。
- 與現代 AI 的區別:專家系統是「基於規則(Rule-based)」且邏輯明確的;而現代機器學習是「基於數據(Data-driven)」且概率性的。專家系統缺乏現代 AI 的學習與泛化能力,維護規則庫非常耗時。
- 應用場景:
- 工業控制:簡單的自動化故障診斷。
- 法規遵循:稅務軟體判斷是否符合扣除額資格。
- 實際例子:
- MYCIN 是 1970 年代著名的專家系統,用於診斷細菌感染。它內建了數百條規則(例如:「如果細菌呈現革蘭氏陽性且形狀為球狀,則可能是…」),能根據輸入的症狀推薦抗生素,其診斷準確率在當時甚至高於部分初級醫師。
Enterprise AI (企業級 AI)
- 中文譯名:企業級 AI
- 簡明定義:指將 AI 技術戰略性地整合到大型組織的營運架構中,以增強業務流程、決策制定和整體效率。
- 深度解析:
- 特定需求:與面向消費者的 AI(如 ChatGPT 免費版)不同,企業 AI 強調安全性、隱私保護(數據不外洩)、可擴展性(Extensibility)與權限管理。
- 整合性:它通常需要與企業現有的系統(如 ERP, CRM, ITSM)進行深度串接。
- 應用場景:
- 內部知識管理:員工透過 AI 搜尋公司內部的海量文檔。
- IT 與 HR 自動化:自動處理重設密碼或入職流程。
- 實際例子:
- 一家跨國公司部署了 Moveworks 的企業 AI 解決方案。當員工電腦壞了,他不需要打電話給 IT 部門,而是直接在 Microsoft Teams 上跟 AI 說。AI 會自動查詢知識庫提供解決方案,如果無效,則自動在 ServiceNow 系統中開立工單並派發給正確的工程師,全程符合公司的資安規範。
Epoch (週期 / 訓練週期)
- 中文譯名:週期 / 訓練週期
- 簡明定義:在機器學習模型訓練過程中,指「完整遍歷一次」所有訓練數據集的過程。
- 深度解析:
- 學習過程:模型通常需要看數據很多次才能學會。一個 Epoch 代表模型已經看過每一張圖片或每一句話一次。
- 調整:訓練通常包含多個 Epoch。如果 Epoch 太少,模型學不會(欠擬合);如果 Epoch 太多,模型會死記硬背(過度擬合)。
- 應用場景:
- 神經網絡訓練:調整超參數時的關鍵設定。
- 實際例子:
- 你有一本 100 頁的數學習題集(訓練數據)。如果你從第 1 頁做到第 100 頁,這就叫完成了 1 個 Epoch。為了考高分,你可能需要把整本習題集重複做 50 遍(50 Epochs),直到你對題型滾瓜爛熟。
F
Foundation Model (基礎模型)
- 中文譯名:基礎模型
- 簡明定義:在廣泛的數據集上訓練的大規模 AI 模型(如 LLM),旨在作為基礎,以便後續能適應各種特定的下游任務和應用。
- 深度解析:
- 通用性:這些模型之所以被稱為「基礎」,是因為它們構成了構建其他應用程式的基石。它們不只包含語言模型,還包括電腦視覺和強化學習模型。
- 適應能力:它們學習了通用的特徵和模式,這使得開發者無需從頭開始訓練模型,而是可以在此基礎上進行微調(Fine-tuning)以解決特定領域的問題。
- 應用場景:
- 多模態應用:同時處理文本、圖像或音訊的任務。
- 企業定製:企業購買基礎模型的 API,然後針對內部的法律或醫療數據進行調整。
- 實際例子:
- GPT-4 是一個基礎模型。開發者可以在其之上建立一個「寫程式助手」,也可以建立一個「法律顧問機器人」,這兩者都依賴於同一個底層基礎模型的語言理解能力。
Fine-tuning (微調)
- 中文譯名:微調
- 簡明定義:採用已經在大數據集上預訓練過的機器學習模型,並使用較小的特定領域數據集對其進行進一步訓練,以適應特定任務的過程。
- 深度解析:
- 效率優勢:微調調整了模型的參數,使其能學習特定任務的模式,而無需重新經歷昂貴的預訓練階段。
- 技術細節:這涉及使用標註好的特定數據(例如:紅燈的圖片)來讓模型專精於某個細分領域(例如:交通號誌識別),從而大幅提升在該任務上的表現。
- 應用場景:
- 企業支援:將通用 LLM 微調為懂公司內部術語的客服機器人。
- 風格遷移:讓 AI 模仿特定作家或品牌的語氣。
- 實際例子:
- 一個通用的圖像識別模型可能認識「車子」。但為了用於自動駕駛,工程師會收集大量「紅燈」與「綠燈」的照片進行微調,讓模型從「認識車子」進化為「能精準判斷何時該煞車」的專用模型。
Few-Shot Learning (少樣本學習)
- 中文譯名:少樣本學習
- 簡明定義:一種機器學習方法,模型僅需極少量的標註範例(通常少於 5 個),就能學會識別新概念或執行新任務。
- 深度解析:
- 學習能力:這與需要數千張圖片才能學會識別貓的傳統深度學習不同。它依賴模型強大的泛化能力,透過類比來理解新任務。
- 變體:包括 Zero-shot(零樣本,無範例)、One-shot(單樣本,一個範例)與 Few-shot(少樣本)。在 GPT 的提示工程中,提供 “N” 個範例往往能顯著提升回答的準確度。
- 應用場景:
- 新類別分類:當收集大量數據太昂貴或不可能時(如罕見疾病識別)。
- 提示工程:在 Prompt 中提供幾個理想的問答對,引導模型輸出特定格式。
- 實際例子:
- 你想讓 AI 將推文分類為「憤怒」或「開心」。你不需要訓練它看一萬條推文,只需在提示詞中給它看 3 條憤怒的推文範例和 3 條開心的推文範例(這就是 Few-shot),它就能立即學會並開始準確分類剩下的推文。
Federated Learning (聯邦學習)
- 中文譯名:聯邦學習
- 簡明定義:一種機器學習技術,允許在多個分散的設備(如手機)上訓練模型,而無需將用戶的原始數據上傳到中央伺服器,從而保護隱私。
- 深度解析:
- 隱私保護:數據保留在本地設備上,只有模型的「更新參數」(如權重的變化)會被加密並發送到雲端進行聚合。
- 去中心化:這解決了數據孤島問題,使得在不共享敏感數據的情況下,多方可以共同訓練一個強大的模型。
- 應用場景:
- 醫療研究:多家醫院共同訓練癌症檢測模型,但無需交換病人的隱私病歷。
- 輸入法優化:手機鍵盤學習新詞彙。
- 實際例子:
- Google 的 Gboard 輸入法使用聯邦學習。當成千上萬的用戶開始輸入一個新流行語(如 “Rizz”),每個人的手機都會在本地學習這個詞。系統只會將「學會新詞」這個數學參數傳回 Google,而不是傳送用戶具體打了什麼字。Google 整合這些參數後,所有用戶的輸入法就都學會了自動修正這個新詞。
Forward Propagation (前向傳播)
- 中文譯名:前向傳播
- 簡明定義:在神經網絡中,輸入數據從輸入層經過隱藏層傳遞到輸出層,經過計算產生預測結果的過程。
- 深度解析:
- 運作流程:網絡將權重(Weights)和偏差(Biases)應用於輸入數據,並透過激活函數(Activation Functions)處理,最終生成輸出。
- 與反向傳播的關係:這是模型「思考」或「預測」的過程;而學習(調整權重)則發生在隨後的「反向傳播(Back Propagation)」階段。
- 應用場景:
- 推論 (Inference):當你實際使用一個訓練好的 AI 模型時,它執行的就是前向傳播。
- 實際例子:
- 當你將一張數字 “7” 的圖片輸入給 AI 時,像素數據一層層通過網絡(前向傳播),每一層都在提取特徵,最後輸出層亮起,告訴你:「這有 99% 的機率是數字 7」。
Feature Learning / Representation Learning (特徵學習 / 表示學習)
- 中文譯名:特徵學習 / 表示學習
- 簡明定義:機器學習中的一套技術,使系統能自動從原始數據中發現並學習所需的特徵表示,用於檢測或分類,取代了傳統的手動特徵工程。
- 深度解析:
- 自動化:在傳統 ML 中,人類必須告訴電腦「找三角形的耳朵」來識別貓。在特徵學習(特別是深度學習)中,模型會自動學會「耳朵」這個特徵的重要性,以及如何識別它。
- 層次化:它通常涉及學習多個層次的表示,從簡單的邊緣到複雜的形狀。
- 應用場景:
- 電腦視覺:自動識別圖像中的物體。
- 自然語言處理:將文字轉換為包含語義的向量(Word Embeddings)。
- 實際例子:
- 在訓練一個 Face ID 系統時,工程師不需要手寫程式碼去定義「鼻子多長」或「眼睛多寬」。透過特徵學習,深度神經網絡會自動從百萬張人臉中找出區分不同人的關鍵特徵(可能是下巴的弧度或眼距的微小差異),即便這些特徵對人類來說很難具體描述。
Forward Chaining (前向鏈接 / 正向推論)
- 中文譯名:前向鏈接 / 正向推論
- 簡明定義:一種推論方法,從可用的數據或事實開始,應用推理規則來提取更多數據,直到得出結論或達到目標。
- 深度解析:
- 數據驅動:與「反向鏈接(Backward Chaining,從目標回推條件)」相反,前向鏈接是「數據驅動」的。它不斷將規則應用於已知事實,推導出新事實。
- 邏輯應用:常用於專家系統(Expert Systems)和生產規則系統。
- 應用場景:
- 自動化監控:當感測器數據發生變化時,觸發一系列反應。
- 事件規劃:根據現有資源規劃可能的行動。
- 實際例子:
- 一個智慧家居系統的邏輯:
- 事實 A:感測器偵測到「客廳沒人」。
- 事實 B:系統時間是「晚上 11 點」。
- 規則:如果「沒人」且「晚於 10 點」,則「關燈」。
- 前向鏈接推論:系統執行「關燈」動作。
- 一個智慧家居系統的邏輯:
G
Generative AI (生成式 AI / 生成式人工智慧)
- 中文譯名:生成式 AI
- 簡明定義:人工智慧的一個分支,專注於創造新的原創內容(如文字、圖像、音訊或影片),其產出是基於對現有數據模式的學習與模仿,。
- 深度解析:
- 創造而非分析:傳統 AI 多用於分類(例如:這是不是垃圾郵件?),而生成式 AI 則能自主構建材料。它通過分析海量訓練數據集中的模式,並利用這些知識來生成具有相似特徵的新數據,。
- 技術基礎:目前主流的生成式 AI 通常基於 Transformer 架構或擴散模型(Diffusion Models)。雖然它們的產出看起來極具創意且類似人類,但系統本身並不具備意識或情感,其本質是預測下一個字或像素的統計模型,。
- 應用場景:
- 內容創作:自動撰寫行銷文案、編寫程式碼、創作詩歌。
- 藝術與設計:生成逼真的照片、藝術插圖或設計原型。
- 實際例子:
- 當使用者對 Midjourney 輸入「一隻在賽博龐克城市中喝咖啡的貓」時,AI 並不是去搜尋一張現有的圖片,而是根據它學過的「賽博龐克」、「貓」和「咖啡」的視覺概念,從零開始「繪製」出一張世界上從未存在過的全新圖片。
GPT / Generative Pre-trained Transformer (生成式預訓練變換器)
- 中文譯名:生成式預訓練變換器
- 簡明定義:由 OpenAI 開發的一系列大型語言模型(LLM),使用 Transformer 架構並經過海量文本數據的預訓練,能夠生成極其像人類的文本,。
- 深度解析:
- 命名拆解:
- Generative (生成式):能夠產出新內容。
- Pre-trained (預訓練):在針對特定任務微調之前,先在廣泛的互聯網數據上進行了通用學習,建立了基礎理解,。
- Transformer (變換器):一種能並行處理序列數據並捕捉長距離上下文依賴的神經網絡架構。
- 演進:從 GPT-3(1750 億參數)到 GPT-4,模型不僅規模變大,還進化為「多模態(Multimodal)」,能同時理解文字與圖像輸入。
- 命名拆解:
- 應用場景:
- 對話系統:如 ChatGPT。
- 文本處理:翻譯、摘要、情感分析、程式碼生成。
- 實際例子:
- 開發者使用 GPT-4 的 API 構建了一個「法律文件分析器」。雖然 GPT-4 在訓練時看過各種類型的文本,但透過其強大的預訓練基礎,它能直接閱讀一份複雜的租賃合約,並準確回答:「這份合約中關於提前終止租約的罰款條款在哪裡?」
GPU / Graphics Processing Unit (圖形處理器)
- 中文譯名:圖形處理器
- 簡明定義:一種最初設計用於快速渲染圖像的專用微處理器,現在因其高效的並行運算能力,成為訓練和運行神經網絡的核心硬體,。
- 深度解析:
- 並行優勢:與 CPU(中央處理器)擅長處理序列任務不同,GPU 擁有數千個核心,能同時處理大量簡單的數學運算。這完美契合了深度學習所需的矩陣乘法運算。
- AI 的引擎:現代大型模型(如 LLM)的訓練需要巨大的算力(Compute),這主要依賴於大規模的 GPU 集群(如 NVIDIA H100/A100)。
- 應用場景:
- 模型訓練:將數月甚至數年的訓練時間縮短至數週。
- 推論 (Inference):在用戶與 AI 互動時,快速生成回應。
- 實際例子:
- 一家 AI 新創公司若要訓練一個類似 Llama 3 的模型,他們不能只用幾台普通的辦公室電腦,而必須租用雲端上配備了數千張 H100 GPU 的伺服器集群,日以繼夜地運算數週才能完成。
Grounding (接地 / 事實落地)
- 中文譯名:接地 / 事實落地
- 簡明定義:將 AI 系統的回答錨定在真實世界的經驗、知識或特定數據上的過程,以提高準確性並減少幻覺。
- 深度解析:
- 解決痛點:純粹的 LLM 有時會因為缺乏上下文或依賴過時訓練數據而「胡說八道」。Grounding 強制模型參考可靠的外部資訊源(如最新的公司手冊或即時新聞)。
- 技術關聯:這通常與 RAG(檢索增強生成)技術結合使用。目的是讓 AI 變得「上下文感知(Context-aware)」,使其回應更具關聯性與可信度。
- 應用場景:
- 企業搜索:確保 AI 引用的數據來自公司內部的真實文檔。
- 客服機器人:根據最新的庫存狀態回答客戶,而不是瞎猜。
- 實際例子:
- 當員工問:「我們公司的差旅費報銷上限是多少?」
- 未接地 (Ungrounded) 的 AI 可能會根據網路上的一般知識回答:「通常是每天 50 到 100 美元。」(這是無效甚至錯誤的建議)。
- 已接地 (Grounded) 的 AI 會先檢索公司內部的《2025 財務規範》,然後回答:「根據規範第 4 條,差旅費上限為每日 120 美元。」
GAN / Generative Adversarial Network (生成對抗網絡)
- 中文譯名:生成對抗網絡
- 簡明定義:一種機器學習模型架構,由兩個神經網絡(生成器與判別器)相互競爭,以生成與真實數據幾乎無法區分的新數據,。
- 深度解析:
- 博弈論機制:
- 生成器 (Generator):負責製造「假」數據(如假照片)。
- 判別器 (Discriminator):負責分辨數據是「真」的(來自真實資料集)還是「假」的(生成器做的)。
- 演化過程:兩者在零和遊戲中不斷對抗。生成器越做越像,判別器越抓越準,最終結果是生成器能產出極度逼真的數據。
- 博弈論機制:
- 應用場景:
- 圖像合成:生成不存在的人臉、將草圖轉為照片。
- 數據增強:在醫療領域生成合成的 X 光片以保護隱私並擴充訓練集。
- 實際例子:
- 網站 “This Person Does Not Exist” 就是 GAN 的經典應用。每次刷新頁面,GAN 都會生成一張看起來完全像真人的照片,但照片中的那個人在現實世界中從未存在過。
Gradient Descent (梯度下降法)
- 中文譯名:梯度下降法
- 簡明定義:一種用於訓練機器學習模型的優化演算法,透過不斷調整模型參數來最小化誤差(損失函數),。
- 深度解析:
- 下山的比喻:想像你在山上(高誤差),想要下到谷底(低誤差),但四周漆黑一片。梯度下降法就是用腳探測四周,找出最陡峭的下坡方向,然後走一步。重複這個過程,最終會到達谷底。
- 數學原理:它計算損失函數相對於權重的梯度,並沿著梯度的反方向更新權重。
- 應用場景:
- 模型訓練:幾乎所有神經網絡(從簡單的線性回歸到複雜的 GPT-4)在訓練階段都依賴此方法來「學習」。
- 實際例子:
- 在訓練一個房價預測模型時,一開始模型預測的房價與真實價格差距很大(誤差高)。梯度下降算法會計算出應該如何微調模型中的「面積權重」和「地段權重」,經過成千上萬次微調後,模型的預測誤差降到最低,預測變得準確。
Genetic Algorithm (遺傳演算法 / 基因演算法)
- 中文譯名:遺傳演算法
- 簡明定義:一種受生物進化論(自然選擇)啟發的搜索與優化演算法,屬於進化計算(Evolutionary Computation)的子集,。
- 深度解析:
- 運作機制:它模擬了「適者生存」的過程。
- 種群 (Population):產生一堆隨機解。
- 選擇 (Selection):挑選表現最好的解作為「父母」。
- 交叉 (Crossover) 與 變異 (Mutation):混合父母的特徵並加入隨機變化,產生「後代」。
- 迭代:這個過程重複多代,直到找到最佳解。
- 運作機制:它模擬了「適者生存」的過程。
- 應用場景:
- 工程設計:設計最符合空氣動力學的子彈頭列車車頭形狀。
- 排程問題:解決複雜的物流配送路徑或工廠排班。
- 實際例子:
- NASA 在設計太空船天線時使用了遺傳演算法。電腦隨機生成了數千種奇怪的金屬絲形狀,模擬它們的收訊能力,保留最好的並進行「雜交」與「突變」。最終演化出一個人類工程師根本想不出來的奇特扭曲形狀,但其性能卻是完美的。
H
Hallucination (幻覺)
- 中文譯名:幻覺
- 簡明定義:指 AI 模型(特別是大型語言模型)生成看似自信且合乎語法,但實際上並非基於真實數據、不合邏輯或完全虛構的內容的現象。
- 深度解析:
- 成因:這通常發生在模型對上下文不確定、過度依賴訓練數據中的某種模式,或缺乏對特定主題的真實理解時。
- 本質:MIT Sloan 指出,這是由於數據和架構限制導致的。本質上,模型是在進行概率預測(預測下一個字),而非檢索事實,因此有時為了讓語句通順,它會「編造」看似合理的細節。
- 風險:這在法律、醫療或新聞領域可能導致嚴重的誤導,因為輸出的資訊往往以事實陳述的形式呈現。
- 應用場景:
- 事實查核 (Fact-checking):這是 RAG(檢索增強生成)技術試圖解決的主要問題,透過引入外部事實來減少幻覺。
- 風險管理:在使用 AI 撰寫專業報告時,必須有人類進行監督(Human-in-the-loop)。
- 實際例子:
- 當你問 AI:「請詳細描述 2024 年台北奧運的開幕式。」雖然現實中 2024 年奧運是在巴黎舉行,但陷入幻覺的模型可能會一本正經地回答:「2024 年台北奧運開幕式在台北大巨蛋舉行,以絢麗的無人機表演展現了台灣科技…」,這完全是虛構的內容。
Hidden Layer (隱藏層)
- 中文譯名:隱藏層
- 簡明定義:人工神經網絡中位於輸入層(Input Layer)與輸出層(Output Layer)之間的神經元層級,不直接與外部環境連接。
- 深度解析:
- 功能核心:這是神經網絡進行特徵提取與複雜計算的地方。每一個隱藏層都會對輸入數據進行加權運算與激活函數處理。
- 深度的意義:「深度學習 (Deep Learning)」中的「深度」,指的就是擁有多個(從三個到數百個)隱藏層的網絡結構。層數越多,模型能學習到的特徵就越抽象、越複雜(如從邊緣線條到完整的物體形狀)。
- 應用場景:
- 複雜模式識別:如人臉識別、語音識別,需要多層隱藏層來逐步解析數據。
- 非線性問題解決:單層網絡只能解決簡單的線性問題,多隱藏層讓模型能處理高度非線性的現實世界問題。
- 實際例子:
- 想像一個識別手寫數字 “8” 的 AI。
- 輸入層接收像素點。
- 第一個隱藏層可能識別出微小的曲線。
- 第二個隱藏層將曲線組合成圓圈。
- 第三個隱藏層發現有兩個圓圈上下相疊。
- 輸出層最終判定這是數字 “8”。 中間這些人類看不見的運算過程,都在隱藏層完成。
- 想像一個識別手寫數字 “8” 的 AI。
Hyperparameter (超參數)
- 中文譯名:超參數
- 簡明定義:在機器學習模型開始訓練之前,需要人為設定的配置變量。它們不是從數據中學習來的,而是用來控制學習過程本身的參數。
- 深度解析:
- 區別:需區分 Parameter (參數) 與 Hyperparameter (超參數)。參數(如權重 Weights)是模型在訓練過程中自動學會的內部變量;而超參數是工程師在訓練前「手動調整」的外部設定。
- 優化:選擇正確的超參數(Hyperparameter Tuning)對於模型性能至關重要,這通常涉及反覆試驗或使用自動化工具。
- 應用場景:
- 模型架構設計:決定神經網絡要有幾層、每層有幾個神經元。
- 訓練控制:設定學習率(Learning Rate)、批次大小(Batch Size)或訓練週期(Epochs)。
- 實際例子:
- 如果把訓練 AI 比喻成烤蛋糕:
- 參數 (Parameters) 是蛋糕糊在烘烤過程中的化學變化(模型內部自己發生的)。
- 超參數 (Hyperparameters) 是你設定的「烤箱溫度」和「烘烤時間」。如果你把溫度(學習率)設得太高,蛋糕會烤焦(模型無法收斂);設得太低,蛋糕永遠烤不熟(訓練太慢)。
- 如果把訓練 AI 比喻成烤蛋糕:
Heuristic (啟發式演算法 / 啟發法)
- 中文譯名:啟發式演算法 / 啟發法
- 簡明定義:一種旨在通過犧牲最優性、完整性或精確度,來換取速度的問題解決技術,通常用於尋找「足夠好」的近似解,而非完美解。
- 深度解析:
- 捷徑思維:當傳統的窮舉法(Brute-force)太慢或無法計算時,啟發法提供了一種「捷徑」或「經驗法則」。它在搜索算法(如 A* 搜尋)中扮演關鍵角色,用來評估哪條路徑「看起來」最有希望。
- 應用領域:廣泛應用於路徑規劃、遊戲博弈與數據挖掘。
- 應用場景:
- 路徑規劃:Google Maps 在計算路線時,不會真的去算地球上每一條小路的組合,而是用啟發法快速排除不合理的方向。
- 防毒軟體:使用啟發式掃描來檢測看似惡意軟體的行為,即使該病毒不在已知資料庫中。
- 實際例子:
- 你在一個巨大的迷宮中找出口。
- 非啟發式(窮舉):走遍每一條死胡同,確保找到絕對最短的路徑,但可能要花幾年。
- 啟發式:遵循一個規則——「總是優先往出口的大致方向走」。這可能不是絕對最短的路(也許會繞點路),但你能以快得多的速度找到出口。
- 你在一個巨大的迷宮中找出口。
Hyperplane (超平面)
- 中文譯名:超平面
- 簡明定義:在機器學習(特別是支持向量機 SVM)中,用於分割不同類別數據的決策邊界。
- 深度解析:
- 維度概念:在二維空間(紙面)上,它是一條線;在三維空間中,它是一個平面;在更高維度的數據空間中,它被稱為「超平面」。
- 分類功能:模型訓練的目標往往是找到一個最佳的超平面,能夠將不同類別的數據點(例如「垃圾郵件」與「正常郵件」)區分開來,且邊界距離最大化。
- 應用場景:
- 分類任務:如區分腫瘤是良性還是惡性。
- 支持向量機 (SVM):這是 SVM 算法的核心概念。
- 實際例子:
- 想像桌子上混雜著紅球和藍球。你拿一根棍子(超平面)放在桌上,試圖將紅球和藍球完全隔開在棍子的兩側。在 AI 運算中,數據可能有幾百個維度(不只是顏色和大小),超平面就是那個負責在高維空間中「劃清界線」的數學邊界。
I
Inference (推論 / 推理)
- 中文譯名:推論 / 推理
- 簡明定義:使用已經訓練好的機器學習模型來對新數據進行預測的過程,。
- 深度解析:
- 訓練 vs. 推論:AI 的生命週期分為兩個階段。「訓練(Training)」是讓模型學習模式的階段(如學生上課),消耗大量算力與時間;「推論(Inference)」則是模型上線後,實際應用所學來回答問題或識別圖像的階段(如學生考試或工作)。
- 算力需求:雖然單次推論比訓練所需的算力少得多,但在大規模應用(如每天數億次查詢的 ChatGPT)中,推論的總體成本和延遲(Latency)是企業關注的重點,。
- 應用場景:
- 即時應用:當你在手機上使用 FaceID 解鎖時,手機晶片正在執行推論。
- 生成式 AI:每一次 ChatGPT 生成回應的過程,都是一次推論運算。
- 實際例子:
- 你已經訓練好一個能分辨「貓」和「狗」的模型。當你上傳一張你家寵物的照片,模型接收照片並在幾毫秒內輸出「這是一隻狗」的結果。這個「接收照片並給出答案」的動作就是推論。
Instruction Tuning (指令微調)
- 中文譯名:指令微調
- 簡明定義:一種機器學習技術,透過提供一組明確的指令或指導方針來微調預訓練模型,使其能適應特定任務或更符合人類意圖的操作,。
- 深度解析:
- 從續寫到對話:基礎的語言模型(Base Model)主要功能是「預測下一個字」(文字接龍)。指令微調改變了這一點,它使用「指令-回應」的配對數據進行訓練,教會模型聽懂像是「請總結這篇文章」或「將此翻譯成法文」這樣的命令,而不僅僅是續寫文字。
- 關鍵技術:這是讓 GPT-3 進化為 ChatGPT 的關鍵步驟之一,通常與 RLHF(人類回饋強化學習)結合使用。
- 應用場景:
- 通用助手:讓模型能執行摘要、翻譯、寫程式等多種指令。
- 企業規範:微調模型使其嚴格遵守「只回答與公司產品相關的問題」的指令。
- 實際例子:
- 未經指令微調的模型:輸入「法國的首都是哪裡?」,它可能會續寫成「法國的首都是哪裡?這個問題很簡單…」(以為你在寫考卷題目)。
- 經過指令微調的模型:輸入「法國的首都是哪裡?」,它會理解這是一個問題並直接回答「巴黎」。
Intelligence Augmentation / IA (智慧增強 / 智能放大)
- 中文譯名:智慧增強 / 智能放大
- 簡明定義:指通過 AI 系統與傳統工具的協同組合,來賦能並提升人類的能力,而非取代人類,。
- 深度解析:
- 哲學差異:與追求完全自主、取代人類角色的「人工智慧(Artificial Intelligence)」不同,IA 強調「人機協作」。目標是讓人類在 AI 的輔助下,決策做得更好、工作效率更高。
- 互補性:利用 AI 擅長的數據處理與模式識別能力,來增強人類擅長的創造力、道德判斷與複雜推理。
- 應用場景:
- 醫療輔助:AI 標示出 X 光片上的可疑區域(IA),由醫生進行最終診斷。
- 程式開發:GitHub Copilot 自動補全程式碼,讓工程師專注於架構設計。
- 實際例子:
- 一位平面設計師使用 AI 工具(如 Photoshop 的 Generative Fill)來快速生成多種背景草圖,然後運用自己的審美與專業技能進行挑選與精修。在這裡,AI 並沒有取代設計師,而是放大了設計師的產出效率與創意廣度。
Interpretability (可解釋性)
- 中文譯名:可解釋性
- 簡明定義:指 AI 模型的架構、邏輯與行為在多大程度上是人類可以內在理解的。
- 深度解析:
- 透明度:可解釋性高的模型(如決策樹或線性回歸)讓人能清楚看到輸入數據是如何一步步被轉換成輸出的。
- 與 Explainability 的區別:雖然常混用,但 Interpretability 通常指模型「本身」的透明度(White-box),而 Explainability (XAI) 往往指為複雜的「黑盒」模型(如深度神經網絡)事後提供解釋的技術,。
- 應用場景:
- 高風險領域:在金融貸款或刑事司法判決中,法規通常要求模型必須具備高度可解釋性,不能只給結果不給理由。
- 除錯:當模型出錯時,開發者需要理解是哪個特徵導致了錯誤判斷。
- 實際例子:
- 一個高可解釋性的房價預測模型會顯示:「房價 = 面積 x 50萬 + 房間數 x 20萬」。任何人都能看懂這個公式。
- 一個低可解釋性的模型(如深度學習)會將數據通過數百層神經元運算,工程師很難直觀地解釋為什麼某個像素的變化導致房價預測增加了 10%。
Inductive Bias (歸納偏差)
- 中文譯名:歸納偏差
- 簡明定義:機器學習演算法為了對未見過的數據進行預測,而對數據分佈所做出的一組預設假設。
- 深度解析:
- 學習的必要條件:如果沒有歸納偏差,模型就無法從有限的訓練數據「概括」到未知數據(這被稱為「沒有免費的午餐定理」)。模型必須「假設」世界是如何運作的才能進行學習。
- 架構決定偏差:不同的神經網絡架構帶有不同的歸納偏差。例如,CNN(卷積神經網絡)假設「相鄰的像素是有關係的」(空間局部性);RNN(循環神經網絡)假設「數據的順序是有意義的」(時間依賴性)。
- 應用場景:
- 模型選擇:處理圖像時選 CNN,處理文字時選 Transformer,就是因為它們的歸納偏差適合該類型的數據。
- 實際例子:
- 當你教小孩(模型)識別「椅子」時,小孩會自然地假設「椅子」不管是紅色的還是藍色的,它還是椅子(顏色不變性),或者椅子倒過來放也還是椅子。這些內建的假設就是人類的歸納偏差,幫助我們不需要看過世界上所有的椅子就能學會認椅子。
Intelligent Agent (智慧代理人)
- 中文譯名:智慧代理人
- 簡明定義:一種自主實體,能夠透過感測器觀察環境,並透過致動器(Actuators)採取行動,以最大化達成目標的機會。
- 深度解析:
- 核心迴圈:感知(Perception)→ 思考/決策 → 行動(Action)。
- 多樣性:範圍從極簡單的恆溫器(溫度低就開暖氣),到極複雜的自動駕駛汽車或火星探測器(需在未知環境中自主導航)。Wikipedia 強調 AI 研究即是關於智慧代理人的研究。
- 應用場景:
- 機器人學:掃地機器人感知障礙物並規劃路徑。
- 軟體代理:高頻交易演算法根據市場數據自動買賣股票。
- 實際例子:
- 一個掃地機器人就是典型的智慧代理人。它感知(撞到牆壁或紅外線偵測到懸崖),決策(應該轉向還是後退),然後行動(驅動輪子轉動),其目標是「最大化清潔面積」並「保持自身安全」。
J
Junction Tree Algorithm (接合樹演算法)
- 中文譯名:接合樹演算法 / 團樹演算法 (Clique Tree Algorithm)
- 簡明定義:一種用於機器學習的演算法,旨在從一般圖結構(General Graphs)中提取邊緣分佈(Marginalization),通常涉及在一種稱為「接合樹」的修改後圖形上執行信念傳播(Belief Propagation)。
- 深度解析:
- 結構轉換:在處理複雜的概率圖模型(如貝氏網絡)時,直接進行推論可能非常困難。此演算法首先將原本可能有迴圈的圖轉換為無迴圈的樹狀結構(即接合樹)。
- 信念傳播:之所以被稱為「樹」,是因為它將數據分支成不同的部分,變量的節點構成了分支。透過這種結構,演算法可以有效地在節點之間傳遞訊息(信念),從而計算出變量的邊緣概率。
- 應用場景:
- 概率推理:在專家系統或醫療診斷系統中,計算在已知某些症狀(證據)的情況下,患某種疾病的精確概率。
- 語音識別與電腦視覺:處理隱藏馬可夫模型(HMM)或其他依賴圖結構的推論任務。
- 實際例子:
- 假設有一個醫療診斷 AI,它使用一個複雜的網絡來表示「抽菸」、「肺癌」與「咳嗽」之間的機率關係(這是一個有迴圈的圖)。為了回答「如果病人咳嗽,他患有肺癌的機率是多少?」這個問題,接合樹演算法會將這個複雜的關係網重新組織成一棵樹,然後透過數學運算快速算出準確的機率值,而不會陷入無限循環的計算中。
K
K-Shot Learning (K 樣本學習)
- 中文譯名:K 樣本學習
- 簡明定義:一種機器學習方法,模型僅透過每個類別 K 個(通常是一個很小的數字,如 1 到 5)標記範例進行學習,。
- 深度解析:
- 與 Few-Shot 的關聯:這與「少樣本學習 (Few-Shot Learning)」概念緊密相關。在大型語言模型 (LLM) 的提示工程中,”Shot” 代表訓練範例。
- 學習效率:傳統深度學習需要成千上萬張圖片來識別一個物體,而 K-Shot Learning 模擬人類的學習能力,能夠從極少量數據中歸納出規則。Moveworks 指出,這允許模型在極少數據的情況下對新數據進行分類和預測。
- 應用場景:
- 提示工程 (Prompt Engineering):在 GPT 提示詞中提供 3 個範例(3-shot)以提高回答準確度。
- 冷啟動問題:當新產品剛上線、幾乎沒有歷史數據時的推薦系統。
- 實際例子:
- 你想讓 AI 寫出特定風格的詩。與其重新訓練整個模型,你只需在提示詞中提供 3 首(K=3)你喜歡的詩作為範例(Context),AI 就能立即模仿這種風格創作出第 4 首詩。
Knowledge Graph (知識圖譜)
- 中文譯名:知識圖譜
- 簡明定義:一種將資訊連接成關係網絡的數據結構,使 AI 系統能夠導航並理解複雜數據集中的關聯性。
- 深度解析:
- 結構化語義:知識圖譜不只是儲存數據,而是儲存「實體 (Entities)」以及它們之間的「關係 (Relationships)」(例如:Steve Jobs –創立–> Apple)。
- 推理基礎:它為 AI 提供了類似人類的背景知識庫,是實現語義搜索 (Semantic Search) 和高級推理 (Reasoning) 的關鍵技術基礎。
- 應用場景:
- 智能搜索:Google 搜尋右側的資訊卡(Knowledge Panel)。
- 推薦系統:根據物品之間的潛在關係(而不僅僅是用戶歷史)進行推薦。
- 實際例子:
- 當你問語音助理:「達文西畫的最著名的那幅畫在哪個博物館?」AI 透過知識圖譜連接了「達文西 (人物)」→ 畫了 →「蒙娜麗莎 (作品)」→ 位於 →「羅浮宮 (地點)」,從而直接給出正確答案,而不是僅僅丟給你一堆關鍵字搜尋結果。
K-Means Clustering (K-Means 分群演算法)
- 中文譯名:K-Means 分群 / K-平均演算法
- 簡明定義:一種向量量化方法,旨在將 n 個觀察對象劃分為 k 個聚類(Cluster),其中每個觀察對象都屬於具有最近均值(聚類中心)的那個聚類。
- 深度解析:
- 無監督學習:這是最經典的無監督學習(Unsupervised Learning)算法之一,不需要預先標記數據。
- 運作邏輯:算法會反覆計算,移動聚類中心,直到群組內的差異最小化,而群組間的差異最大化。
- 應用場景:
- 市場區隔:根據消費行為將客戶自動分成幾類(如:高消費群、促銷敏感群)。
- 圖像壓縮:減少圖像中的顏色數量。
- 實際例子:
- 一家服飾電商擁有一百萬名用戶的購買數據。使用 K-Means (設 K=5),系統自動將用戶分成 5 個群體。行銷人員發現其中一群(Cluster 3)專買「週末特價品」,於是針對這群人發送專屬的折扣電子報。
Knowledge Distillation (知識蒸餾)
- 中文譯名:知識蒸餾
- 簡明定義:將知識從一個大型機器學習模型(教師模型)轉移到一個較小模型(學生模型)的過程。
- 深度解析:
- 模型壓縮:大型模型(如 GPT-4)雖然強大但運算成本高昂且緩慢。知識蒸餾讓小模型學習大模型的輸出機率分佈,使其在保留大部分性能的同時,體積更小、速度更快。
- 部署優勢:這對於在手機或邊緣設備(Edge Devices)上運行 AI 至關重要。
- 應用場景:
- 移動端 AI:讓手機鍵盤的自動修正功能具備大型模型的準確度,但能在離線狀態下運行。
- 即時應用:降低自動駕駛汽車的推論延遲。
- 實際例子:
- 一家公司訓練了一個巨大的 AI 模型來識別垃圾郵件,準確率 99.9%,但它太大了,無法放入手機 App。工程師使用知識蒸餾,讓這個大模型「教導」一個只有其 1/10 大小的小模型。最終,小模型學會了模仿大模型的判斷邏輯,準確率達到 98%,且可以輕鬆安裝在用戶的手機上。
Kernel Method (核方法 / 核技巧)
- 中文譯名:核方法
- 簡明定義:機器學習中的一類算法(最著名的是支持向量機 SVM),用於模式分析,旨在發現數據集中的一般關係(如分類、排名等)。
- 深度解析:
- 維度提升:核技巧 (Kernel Trick) 的核心在於將低維度的線性不可分數據,映射到高維度空間,使其變得線性可分,而無需顯式地計算該高維空間的坐標。
- 模式識別:這使得線性分類器也能解決非線性問題。
- 應用場景:
- 手寫識別:區分形狀複雜的數字。
- 生物資訊學:基因序列分類。
- 實際例子:
- 想像桌上有紅豆和綠豆混在一起(二維平面),你無法用一根直尺(線性分類器)把它們分開。使用核方法,就像是猛拍桌子讓豆子飛起來(映射到三維空間),在空中的某個瞬間,你就可以插入一張紙(超平面),完美地將紅豆和綠豆隔開。
Knowledge Representation and Reasoning / KR&R (知識表示與推理)
- 中文譯名:知識表示與推理
- 簡明定義:AI 的一個領域,致力於以電腦系統可利用的形式來表示關於世界的資訊,以便解決複雜任務(如醫療診斷或自然語言對話)。
- 深度解析:
- 轉化人類知識:它結合了心理學(人類如何解決問題)與邏輯學(自動推理)。常見的形式包括語義網 (Semantic Nets)、框架 (Frames)、規則 (Rules) 和本體論 (Ontologies)。
- 不僅是數據:與純粹的統計學習不同,KR&R 強調邏輯結構與因果關係的顯式表達。
- 應用場景:
- 專家系統:將醫生的診斷邏輯編碼成規則。
- 法律 AI:將法律條文轉化為邏輯代碼以自動審查合約。
- 實際例子:
- 在開發一個「自動除錯」的 AI 時,工程師不只是餵給它程式碼,還建立了一套知識表示:「如果出現錯誤代碼 500,且伺服器日誌顯示連接超時,則推論為資料庫過載。」這種顯式的邏輯結構讓 AI 能像資深工程師一樣進行推理和解釋。
K-Nearest Neighbors / k-NN (K-近鄰演算法)
- 中文譯名:K-近鄰演算法
- 簡明定義:一種非參數監督學習方法,用於分類和回歸。即「物以類聚」,根據最近的 k 個鄰居的類別來決定新數據的類別。
- 深度解析:
- 懶惰學習 (Lazy Learning):它在訓練階段幾乎不做什麼,直到需要預測時才開始計算新數據與所有舊數據的距離。
- 直觀簡單:它是機器學習中最簡單但有時非常有效的算法之一。
- 應用場景:
- 推薦系統:找出與你有相似觀看歷史的 K 個用戶,看他們還看了什麼。
- 異常檢測:如果一個數據點周圍沒有「鄰居」,它可能就是異常值。
- 實際例子:
- 想像你走進一個充滿陌生人的派對,你想知道自己屬於哪一掛(分類)。你看看離你最近的 5 個人(K=5),發現其中 4 個是工程師,1 個是設計師。根據 k-NN 邏輯,你很可能也是個工程師。
Knowledge Extraction (知識抽取)
- 中文譯名:知識抽取
- 簡明定義:從結構化(資料庫)和非結構化(文本、圖像)來源中創建知識的過程。
- 深度解析:
- 資訊變知識:這是構建知識圖譜的第一步。它涉及從雜亂的文檔中識別出實體(Entity Extraction)和它們之間的關係。
- 機器可讀:目標是將人類可讀的文檔轉化為機器可解釋的格式。
- 應用場景:
- 自動化歸檔:從掃描的發票中自動提取「日期」、「金額」和「供應商」。
- 新聞監控:從每天數萬篇新聞中抽取「誰收購了誰」的商業情報。
- 實際例子:
- 一家律師事務所使用 AI 掃描數千份過往的判決書(非結構化文本)。知識抽取算法自動從中抓取出:「法官姓名」、「引用法條」、「判決結果」等關鍵資訊,並整理成結構化的資料庫,讓律師能瞬間查詢「某法官在類似案件中的判決傾向」。
L
Large Language Model / LLM (大型語言模型)
- 中文譯名:大型語言模型
- 簡明定義:一種深度學習模型,在海量數據集上進行訓練,能夠理解、生成並預測類似人類的文本,,。
- 深度解析:
- 運作機制:這些模型本質上是神經網絡(通常基於 Transformer 架構 ),其工作原理是預測單詞序列。
- 規模:它們的特徵在於擁有大量的「參數」(Parameters),即模型中可調整的變量,數量通常達到數十億甚至更多,。這使得模型具備廣泛的認知能力,而不僅限於特定任務。
- 演進:需要巨大的算力與數據來訓練,能夠處理編碼、聊天、科學分析等多種任務,。
- 應用場景:
- 內容生成:撰寫電子郵件、文章或程式碼。
- 對話系統:驅動像 ChatGPT 這樣的聊天機器人。
- 實際例子:
- GPT-4、BERT、PaLM 和 Llama 都是著名的大型語言模型,。當你要求 ChatGPT 「寫一首關於台北雨天的詩」時,背後的 LLM 正在根據它閱讀過的數十億文本,逐字預測並生成最符合語義與韻律的下一個字。
Latent Space (潛在空間 / 隱含空間)
- 中文譯名:潛在空間 / 隱含空間
- 簡明定義:機器學習模型(如神經網絡)創建的數據壓縮表示形式,其中相似的數據點在空間距離上會靠得更近。
- 深度解析:
- 降維與特徵:模型將複雜的原始數據(如圖片的像素)壓縮成低維度的數學向量。在這個抽象空間中,具有相似特徵的項目會群聚在一起。
- 生成基礎:這是許多生成式 AI(如擴散模型)的運作場域。擴散模型學習數據點如何在潛在空間中擴散,從而能生成新圖像。
- 應用場景:
- 圖像生成:從雜訊中「解碼」出位於潛在空間特定坐標的圖像。
- 推薦系統:如果用戶喜歡電影 A,系統會推薦在潛在空間中距離 A 最近的電影 B。
- 實際例子:
- 在一個訓練良好的潛在空間中,「國王」與「女王」這兩個詞的向量距離,會非常接近「男人」與「女人」之間的距離。這意味著模型在這個數學空間中自動學會了「性別」這個抽象概念,而不需要人類顯式編程。
Loss Function (損失函數)
- 中文譯名:損失函數 / 代價函數 (Cost Function)
- 簡明定義:機器學習模型在訓練過程中試圖最小化的一個數學函數,它量化了「模型的預測值」與「真實值」之間的差距,。
- 深度解析:
- 導航儀:它是模型優化的指南針。通過計算損失(誤差),模型知道自己的預測有多糟糕。
- 優化過程:通常結合梯度下降(Gradient Descent)算法使用。算法會根據損失函數來調整模型的參數(權重),目的是讓損失值越來越小,直到模型預測準確,。
- 應用場景:
- 模型訓練:這是所有監督學習的核心指標。
- 實際例子:
- 你在教 AI 射箭(預測目標)。第一次它射偏了 10 米,損失函數計算出「誤差 = 10」。模型根據這個反饋調整姿勢(更新權重)。第二次射偏了 2 米,損失函數為「2」。模型繼續微調,直到損失函數接近 0,這時箭就射中了紅心。
Long Short-Term Memory / LSTM (長短期記憶網絡)
- 中文譯名:長短期記憶網絡
- 簡明定義:一種特殊的人工遞歸神經網絡(RNN)架構,專門設計用於處理由序列數據構成的任務,並解決了傳統 RNN 難以記住長期依賴關係的問題。
- 深度解析:
- 記憶機制:與標準的前饋神經網絡不同,LSTM 具有反饋連接,使其成為一種「通用計算機」(圖靈完備), 。
- 處理序列:它不僅能處理單個數據點(如圖像),還能處理整個數據序列(如語音或影片)。它的結構允許它在長序列中保留重要資訊並遺忘無關資訊。
- 應用場景:
- 語音識別:理解連續的口語句子。
- 手寫識別:識別未分割的連續手寫文字 。
- 實際例子:
- 當你閱讀一本長篇小說時,讀到第 100 頁時你還記得第 1 頁主角的名字。傳統 RNN 讀到第 10 頁可能就忘了主角是誰,但 LSTM 擁有特殊的「記憶單元」,能讓它在處理完整個章節後,依然記得開頭的關鍵細節,這對翻譯長句子或分析影片情節至關重要。
LoRA (Low-Rank Adaptation / 低秩適應)
- 中文譯名:低秩適應 / LoRA 微調
- 簡明定義:一種用於微調大型模型的高效方法,通過僅更新模型中極小部分的參數來適應新任務。
- 深度解析:
- 資源效率:與重新訓練整個大模型相比,LoRA 更加快速且資源消耗更低。它凍結預訓練模型的權重,並將可訓練的秩分解矩陣注入到 Transformer 架構的每一層中。
- 靈活性:這使得開發者可以在普通的 GPU 上微調巨大的模型,並輕鬆切換不同的任務適配器。
- 應用場景:
- 風格定製:讓 Stable Diffusion 模型學會畫特定畫風(如「吉卜力風格」)或特定角色。
- 特定領域適應:快速讓 LLM 學會醫學術語。
- 實際例子:
- 你下載了一個 10GB 的通用繪圖 AI 模型。你想讓它專門畫你的寵物狗,但你沒有昂貴的超級電腦來重新訓練它。你使用 LoRA 技術,只需訓練一個幾十 MB 的小文件(LoRA adapter),掛載到大模型上,它就能完美畫出你的狗,而無需改變原本那 10GB 的基礎模型。
Latency (延遲)
- 中文譯名:延遲
- 簡明定義:指 AI 系統從接收輸入到生成相應輸出之間的時間差。
- 深度解析:
- 性能指標:在實時應用中,延遲是關鍵的用戶體驗指標。對於大型語言模型,延遲通常受模型大小、硬體算力(Compute)以及輸入輸出的長度(Tokens)影響。
- 權衡:通常模型越精確、越龐大,推論所需的計算量越大,導致延遲越高。
- 應用場景:
- 語音助手:Siri 或 Alexa 必須在幾毫秒內響應,否則用戶會感到卡頓。
- 自動駕駛:必須達到極低延遲,才能即時反應路況。
- 實際例子:
- 你在聊天機器人輸入「你好」,如果它立刻回答,這是低延遲。如果轉圈圈過了 5 秒才跳出「你好」,這就是高延遲。在客服場景中,高延遲會顯著降低滿意度。
Lazy Learning (懶惰學習)
- 中文譯名:懶惰學習
- 簡明定義:一種機器學習方法,系統在訓練階段僅儲存數據,將「如何歸納」的計算過程推遲到實際收到查詢(Query)時才進行,。
- 深度解析:
- 對比:與「急切學習 (Eager Learning)」相反,後者在訓練時就構建好通用的目標函數。
- 特點:懶惰學習在訓練時非常快(因為幾乎不做事),但在預測時可能較慢,因為它要現場計算與所有存儲數據的關係。
- 應用場景:
- 推薦系統:基於最近鄰居的推薦。
- 實際例子:
- k-近鄰演算法 (k-NN) 是典型的懶惰學習。它不會預先算出「貓」和「狗」的邊界線。只有當你拿一張新照片問它「這是什麼?」時,它才開始翻找資料庫,看這張照片離哪些舊照片最近,然後當場告訴你答案。
Logic Programming (邏輯編程)
- 中文譯名:邏輯編程
- 簡明定義:一種程式設計範式,主要基於形式邏輯。程式由關於問題領域的事實(Facts)和規則(Rules)組成的邏輯語句構成。
- 深度解析:
- 宣告式:程式設計師描述「什麼是正確的」(What),而不是「該怎麼做」(How)。
- AI 淵源:它是符號人工智慧(Symbolic AI)的重要組成部分,Prolog 是其中最著名的語言家族。
- 應用場景:
- 專家系統:醫療診斷規則。
- 自然語言處理:早期的語法解析。
- 實際例子:
- 在 Prolog 中,你寫下規則:「所有人都會死 (All men are mortal)」和事實:「蘇格拉底是人 (Socrates is a man)」。當你查詢「蘇格拉底會死嗎?」時,邏輯編程系統會自動推導出「是」,而不需要你編寫
if-then的流程控制代碼。
- 在 Prolog 中,你寫下規則:「所有人都會死 (All men are mortal)」和事實:「蘇格拉底是人 (Socrates is a man)」。當你查詢「蘇格拉底會死嗎?」時,邏輯編程系統會自動推導出「是」,而不需要你編寫
M
Machine Learning / ML (機器學習)
- 中文譯名:機器學習
- 簡明定義:人工智慧的一個子領域,提供系統自動學習並從經驗中改進的能力,而無需進行明確的編程,。
- 深度解析:
- 核心機制:透過開發演算法和統計模型,使電腦能分析數據並從中推斷出模式,。
- 學習範式:主要分為三類:監督式學習(有標籤數據)、非監督式學習(無標籤數據)和強化學習(透過獎勵與懲罰學習),。它是現代 AI 的核心驅動力,與傳統需要編寫每一條規則的程式設計形成對比。
- 應用場景:
- 預測分析:根據歷史數據預測未來事件。
- 分類任務:將電子郵件分類為垃圾郵件或正常郵件。
- 實際例子:
- 一家電信公司使用機器學習演算法分析客戶的過去行為數據,以預測哪些客戶最有可能流失(Churn),並提前提供優惠挽留。
Multimodal Model (多模態模型)
- 中文譯名:多模態模型 / 多模態 AI
- 簡明定義:一種能夠理解、處理並生成多種類型數據(如文字、圖像、音訊和影片)的 AI 模型,。
- 深度解析:
- 跨感官能力:與僅能處理文字的單模態模型不同,多模態模型(如 GPT-4)能同時接受圖像與文字輸入,。這使其具備類似人類的綜合感知能力,例如「看」懂圖片內容並用文字描述出來。
- 技術整合:結合了自然語言處理(NLP)與電腦視覺(Computer Vision)等技術。
- 應用場景:
- 視覺問答:上傳一張圖表並詢問 AI 其中的數據含義。
- 內容創作:從文字描述生成影片或圖像。
- 實際例子:
- 使用者上傳一張壞掉的自行車照片給 AI,並問:「這個零件叫什麼?該怎麼修?」多模態模型能識別照片中的特定齒輪,並提供文字維修指南。
Mixture of Experts / MoE (混合專家模型)
- 中文譯名:混合專家模型
- 簡明定義:一種機器學習技術,訓練多個專門的子模型(稱為「專家」),並根據輸入的內容動態決定由哪些專家來處理該任務。
- 深度解析:
- 分而治之:MoE 架構不使用單一巨大的神經網絡處理所有請求,而是利用一個「門控網路(Gating Network)」將問題路由給最擅長該領域的專家模型。
- 效益:這允許模型在參數極大(例如數兆)的情況下,每次推論只活化一小部分參數,從而顯著降低計算成本並提高效率。
- 應用場景:
- 大型語言模型:如 Mistral 或 GPT-4 的某些版本,用於處理極其廣泛的主題。
- 實際例子:
- 想像一個由數百名醫生組成的團隊(模型)。當病人進來時,護理師(門控網路)判斷病情,若是心臟問題就只叫醒心臟科專家(專家 A),若是骨折就叫醒骨科專家(專家 B)。這就是 MoE 的運作方式,避免了讓所有醫生同時診斷每一個病人。
Monte Carlo Tree Search / MCTS (蒙地卡羅樹搜尋)
- 中文譯名:蒙地卡羅樹搜尋
- 簡明定義:一種用於決策過程的啟發式搜尋演算法,特別常用於遊戲博弈中。
- 深度解析:
- 隨機模擬:它透過隨機模擬未來的可能步驟來評估當前決策的好壞。它結合了樹搜尋的精確性與隨機採樣的廣度。
- 突破性應用:這是 AlphaGo 戰勝人類圍棋冠軍的關鍵技術之一,它將傳統的樹搜尋方法隨機化,以處理圍棋這種具有巨大搜尋空間的遊戲。
- 應用場景:
- 棋類遊戲:Go(圍棋)、西洋棋。
- 複雜規劃:需要在不確定環境中進行多步決策的任務。
- 實際例子:
- 在下圍棋時,AI 無法算出所有可能的幾百步之後的結局。MCTS 會從當前局面隨機「試玩」幾千局直到終局,如果發現某一步棋導致「試玩」的勝率特別高,它就會選擇這一步。
Markov Decision Process / MDP (馬可夫決策過程)
- 中文譯名:馬可夫決策過程
- 簡明定義:一個用於模擬決策制定的數學框架,適用於結果部分隨機、部分受決策者控制的情境。
- 深度解析:
- 強化學習基礎:MDP 是強化學習(Reinforcement Learning)的理論基礎。它描述了狀態(States)、行動(Actions)、轉換機率和獎勵(Rewards)之間的關係。
- 核心假設:未來的狀態僅取決於當前狀態與採取的行動,而與過去的歷史無關(馬可夫性質)。
- 應用場景:
- 機器人路徑規劃:決定機器人下一步該往哪走以避開障礙並到達目標。
- 自動化控制:優化動態系統的決策。
- 實際例子:
- 設計一個掃地機器人時,地圖是網格(狀態)。機器人選擇「向前移動」(行動)。但因為輪子打滑(隨機性),它有 90% 機率真的向前,10% 機率原地不動。MDP 模型幫助機器人計算在這種不確定性下,如何規劃一系列行動以最快速度掃完房間並獲得「乾淨」的獎勵。
Meta Prompt / System Prompt (元提示詞 / 系統提示詞)
- 中文譯名:元提示詞 / 系統提示詞
- 簡明定義:在使用者開始互動之前,提供給 AI 模型的一組幕後指令,用於設定 AI 的行為、語氣或邊界。
- 深度解析:
- 隱形指令:這些指令通常對使用者是不可見的,但它們定義了模型的「人設」。
- 控制權:它能防止模型越獄或回答不當內容,並確保模型專注於特定任務。
- 應用場景:
- 角色扮演:設定 AI 為「嚴厲的數學老師」或「友善的客服」。
- 企業規範:指示 AI 「只能回答有關本公司產品的問題,拒絕回答政治問題」。
- 實際例子:
- 當你在使用一個英語教學 App 的 AI 聊天功能時,開發者在後台已經輸入了一段 Meta Prompt:「你是一個有耐心的英語家教,請總是糾正學生的語法錯誤,並用簡單的英語解釋,不要使用中文回答。」這使得 AI 無論如何都會堅持用英語教學。
Multi-hop Reasoning (多跳推理)
- 中文譯名:多跳推理
- 簡明定義:指 AI 模型透過連接文本中或不同來源的多個資訊片段來檢索答案的過程,而不是直接從單一段落中提取資訊。
- 深度解析:
- 邏輯鏈條:這要求模型具備更高的閱讀理解能力,必須先找到線索 A,再根據線索 A 找到線索 B,最終推導出結論。這在機器閱讀理解(Machine Reading Comprehension)中是一個進階能力。
- 應用場景:
- 複雜問答系統:回答需要跨文檔綜合資訊的問題。
- 法律分析:結合多條法規與案例事實進行推論。
- 實際例子:
- 問題:「《哈利波特》作者的出生地在哪個國家?」
- 單跳推理(直接檢索):找含有「JK羅琳出生於英國」的句子。
- 多跳推理:
- 第一跳:找到「《哈利波特》的作者是 J.K. 羅琳」。
- 第二跳:找到「J.K. 羅琳出生於 Yate」。
- 第三跳:找到「Yate 位於英國」。
- 結論:英國。
Multi-agent System / MAS (多代理系統)
- 中文譯名:多代理系統
- 簡明定義:由多個互動的智慧代理(Intelligent Agents)組成的電腦系統。
- 深度解析:
- 集體智慧:這些代理可以是獨立的軟體或機器人,它們共同解決單一代理或單體系統無法解決的複雜問題。
- 分散式 AI:它是分散式人工智慧(Distributed AI)的一個子領域,強調代理之間的協作、競爭或談判。
- 應用場景:
- 交通控制:每個紅綠燈都是一個代理,互相溝通以優化全市車流。
- 供應鏈管理:不同公司的庫存系統作為代理自動協商訂單。
- 實際例子:
- 在一個自動化倉儲中,數百台搬運機器人(Agents)同時移動。如果由中央電腦控制每一台的每一步,計算量會過大。使用 MAS,每台機器人都是一個獨立的代理,它們會互相「溝通」(例如:「我要過路口,你先等一下」),從而實現高效且無碰撞的物流運作。
Model Chaining (模型鏈接)
- 中文譯名:模型鏈接
- 簡明定義:一種資料科學技術,將多個機器學習模型依序連接起來,以進行預測或分析。
- 深度解析:
- 管線化 (Pipeline):前一個模型的輸出直接作為下一個模型的輸入。這允許開發者將複雜任務拆解為多個簡單的子任務,每個子任務由專門的模型處理。
- 應用場景:
- 語音翻譯:語音轉文字模型 → 機器翻譯模型 → 文字轉語音模型。
- 複雜決策:情感分析模型 → 分類模型 → 推薦模型。
- 實際例子:
- 一個自動會議記錄系統可能包含 Model Chaining:
- 模型 A(語音識別):將錄音轉成文字。
- 模型 B(說話者識別):標記是誰說的。
- 模型 C(摘要模型):將標記好的文字生成摘要。 最終輸出給用戶的是一份帶有發言人標記的精簡會議紀要。
- 一個自動會議記錄系統可能包含 Model Chaining:
N
Natural Language Processing / NLP (自然語言處理)
- 中文譯名:自然語言處理
- 簡明定義:人工智慧的一個子領域,專注於電腦與人類語言之間的互動,目標是讓電腦能夠閱讀、解讀、理解並產生有意義的人類語言,。
- 深度解析:
- 核心目標:將非結構化的自然語言數據(如自由文本)轉換為電腦可以處理的標準化結構。
- 跨領域結合:它結合了語言學、電腦科學和資訊工程,涉及語法分析、語義理解等多層次處理,。它是現代 AI 與人類溝通的基礎橋樑。
- 應用場景:
- 機器翻譯:如 Google 翻譯。
- 情感分析:分析社群媒體評論是正面還是負面。
- 語音助手:Siri 或 Alexa 理解你的口語指令。
- 實際例子:
- 當你在電子郵件過濾器中收到一封信,系統自動識別出內容包含「中獎」、「匯款」等詞彙並將其歸類為垃圾郵件,這就是 NLP 技術在背後運作。
Neural Network (神經網絡 / 類神經網絡)
- 中文譯名:神經網絡 / 類神經網絡
- 簡明定義:一種受人類大腦結構啟發的機器學習模型,由多層相互連接的節點(神經元)組成,用於從數據中學習模式,,。
- 深度解析:
- 結構:包含輸入層、隱藏層(處理計算)和輸出層。每個神經元接收輸入,進行計算(通常涉及權重和偏差),然後產生輸出傳遞給下一層,。
- 學習機制:透過分析統計模式來學習技能。即便設計這些網絡的專家,有時也難以完全解釋隱藏層中發生的複雜運算過程。它是深度學習(Deep Learning)的基礎架構。
- 應用場景:
- 圖像識別:手寫數字識別、人臉辨識。
- 複雜預測:股票市場分析、天氣預報。
- 實際例子:
- 想像教一個小孩(神經網絡)認識「貓」。你給他看一千張照片,每看一張就告訴他「這是貓」或「這不是貓」。網絡內部的神經元會自動調整連接強度(權重),最後學會了貓的特徵(尖耳朵、鬍鬚),即便再看到一張從未見過的貓的照片,也能準確識別。
Natural Language Generation / NLG (自然語言生成)
- 中文譯名:自然語言生成
- 簡明定義:AI 的一個子領域,專注於將結構化數據轉換為自然流暢的書面或口語語言,。
- 深度解析:
- 數據變故事:NLG 的作用與 NLU(自然語言理解)相反。NLU 是將文字讀入並理解,NLG 則是將電腦內部的數據輸出成人類可讀的報告或回應。
- 自動化:它可以用於自動生成報告,或在聊天機器人中生成動態回應,甚至配合文字轉語音(TTS)系統朗讀出來。
- 應用場景:
- 商業報告:自動將 Excel 銷售數據寫成一段文字摘要。
- 個人化訊息:根據用戶行為生成專屬的行銷信件。
- 實際例子:
- 股市 App 在收盤後自動推播:「今日台積電上漲 2%,成交量放大…」。這段文字通常不是人寫的,而是 NLG 系統根據當日的交易數據庫自動生成的財經新聞快訊。
Natural Language Understanding / NLU (自然語言理解)
- 中文譯名:自然語言理解
- 簡明定義:NLP 的一個子題,專注於分析文本以獲取語義(Meaning),即理解上下文、情感和意圖。
- 深度解析:
- 超越字面:NLU 試圖解決自然語言的歧義性(Ambiguity)。同一個詞在不同語境下有不同意思,NLU 負責判斷該詞在當下的確切含義(例如「蘋果」是指水果還是科技公司)。
- 意圖識別:識別說話者「想要做什麼」(Intent),這是聊天機器人能否準確服務的關鍵。
- 應用場景:
- 客服機器人:區分客戶是想「退貨」還是「查詢訂單」。
- 輿情分析:理解網民評論背後的真實情緒。
- 實際例子:
- 你對銀行機器人說:「我的卡丟了。」NLU 模型會分析這句話,提取出意圖(掛失)和實體(信用卡),然後觸發掛失流程。如果沒有 NLU,電腦可能只會把它當作一串無意義的字符。
Named Entity Recognition / NER (命名實體識別)
- 中文譯名:命名實體識別
- 簡明定義:資訊抽取的一項子任務,旨在定位非結構化文本中的「命名實體」並將其分類為預定義的類別(如人名、組織、地點、時間等)。
- 深度解析:
- 結構化關鍵:這是將雜亂文字轉化為結構化數據的第一步。系統必須能識別「賈伯斯」是一個人,「蘋果」是一家公司(而非水果),「加州」是一個地點。
- 應用廣泛:在醫療領域可用於提取藥物名稱和病症代碼;在金融領域用於提取公司名稱和金額。
- 應用場景:
- 自動履歷篩選:從 PDF 履歷中抓取姓名、學校、公司名稱。
- 新聞監控:自動標記新聞中出現的所有政治人物和地點。
- 實際例子:
- AI 閱讀一句話:「馬斯克於週二在德州宣佈了特斯拉的新計畫。」NER 系統會輸出:
- Person: 馬斯克
- Date: 週二
- Location: 德州
- Organization: 特斯拉
- AI 閱讀一句話:「馬斯克於週二在德州宣佈了特斯拉的新計畫。」NER 系統會輸出:
N-Shot Learning (N 樣本學習)
- 中文譯名:N 樣本學習
- 簡明定義:一種機器學習概念,指提供給模型多少個訓練範例(Shot)來引導其進行分類或預測。
- 深度解析:
- 變體:
- Zero-shot (零樣本):不給任何範例,直接問模型(例如:「將這句話翻譯成法文」)。
- Few-shot (少樣本):給予少量範例(通常 N=1 到 5),。
- 提示工程:在大型語言模型(LLM)的提示詞(Prompt)中,提供 “N” 個範例通常能顯著提升模型回答的準確度與格式規範性。
- 變體:
- 應用場景:
- 新任務適應:無需重新訓練模型,只需在輸入中加上範例即可讓 AI 學會新格式。
- 實際例子:
- 你想讓 ChatGPT 幫你把推文分類成「生氣」或「開心」。
- Zero-shot: “這條推文是生氣還是開心?:’我恨下雨’。”
- Few-shot (3-shot): “範例1:’好棒的天氣’ -> 開心。範例2:’塞車真煩’ -> 生氣。範例3:’中獎了’ -> 開心。請分類:’我恨下雨’ -> ?” (通常這種方式效果更好)。
NeRF / Neural Radiance Fields (神經輻射場)
- 中文譯名:神經輻射場
- 簡明定義:一種利用神經網絡從一組 2D 圖像創建 3D 場景的方法。
- 深度解析:
- 視圖合成:NeRF 能夠學習光線在場景中如何傳播(輻射場),從而能夠生成從未拍攝過的角度的逼真圖像(View Synthesis)。
- 技術突破:它可以用於相片級真實感的渲染,將靜態的幾張照片轉換為可互動的 3D 模型。
- 應用場景:
- 虛擬實境 (VR):低成本建立真實世界的 3D 複製品。
- 電子商務:讓消費者可以 360 度旋轉查看商品,而無需昂貴的 3D 掃描設備。
- 實際例子:
- Google Maps 的 “Immersive View”(沉浸式視圖)功能背後就使用了類似 NeRF 的技術。它將數百萬張街景照片拼接並計算,讓你能在手機上像無人機一樣飛越並從任意角度觀看東京鐵塔的 3D 模型,而不僅僅是看平面的衛星圖。
Naive Bayes Classifier (樸素貝氏分類器)
- 中文譯名:樸素貝氏分類器
- 簡明定義:一系列基於貝氏定理的簡單概率分類器,其核心特點是假設特徵之間相互獨立(因此稱為「樸素」)。
- 深度解析:
- 簡單高效:儘管「特徵獨立」的假設在現實中很少成立(例如「銀行」和「帳戶」這兩個詞在文本中常同時出現,並非獨立),但該算法在實踐中(特別是文本分類)表現出奇地好且運算速度極快。
- 應用場景:
- 垃圾郵件過濾:這是最經典的應用。
- 情感分類:判斷文本是正面還是負面。
- 實際例子:
- Gmail 的早期垃圾郵件過濾器使用 Naive Bayes。它計算郵件中出現「威而鋼」、「免費」、「匯款」等詞的機率。如果這些詞同時出現的綜合機率超過某個閾值,郵件就會被丟進垃圾桶。
Neuro-fuzzy (神經模糊系統)
- 中文譯名:神經模糊系統
- 簡明定義:結合了人工神經網絡(Neural Networks)與模糊邏輯(Fuzzy Logic)優點的混合智慧系統。
- 深度解析:
- 互補性:神經網絡擅長從數據中學習模式(黑盒子),而模糊邏輯擅長處理不精確性並提供可解釋的推理規則(白盒子)。兩者結合(如 ANFIS)試圖創造出既能學習又具備可解釋性的模型。
- 應用場景:
- 智慧控制系統:如冷氣機的溫度控制(不只是開/關,而是根據舒適度微調)。
- 醫療診斷:處理症狀描述的模糊性(如「有點痛」)。
- 實際例子:
- 一台智慧型洗衣機使用 Neuro-fuzzy 系統。它透過感測器偵測衣物重量和混濁度(數據輸入),利用模糊邏輯判斷衣物是「稍微髒」還是「非常髒」,並自動調整水位和洗滌時間。
O
Overfitting (過度擬合 / 過擬合)
- 中文譯名:過度擬合 / 過擬合
- 簡明定義:指機器學習模型與訓練數據的擬合程度過高,導致它記住了數據中的雜訊和細節,從而在面對未見過的新數據時表現不佳(預測能力差)的現象,,。
- 深度解析:
- 死記硬背:這就像是一個學生為了考試死背了練習題的所有答案,但並沒有真正理解背後的原理。當考試題目稍微變換數字時,他就無法作答。
- 模型複雜度:通常發生在模型過於複雜(參數太多)而數據量相對不足時。模型捕捉了訓練數據中的隨機波動而非一般規律。
- 解決方案:可透過正則化(Regularization)、增加訓練數據(Data Augmentation)或早停法(Early Stopping)來緩解。
- 應用場景:
- 金融預測:一個過度擬合的模型可能完美解釋了過去一個月的股價波動,但完全無法預測明天的走勢。
- 醫療診斷:模型記住了特定醫院機器的雜訊特徵,換到另一家醫院的 X 光片就失效。
- 實際例子:
- 訓練一個分辨「貓」的 AI,如果訓練圖片中的貓都在綠色草地上。過度擬合的模型可能會認為「綠色背景」是貓的特徵之一。當你給它看一張在室內沙發上的貓的照片時,因為沒有綠色背景,它就判斷這「不是貓」。
Optimization (優化 / 最佳化)
- 中文譯名:優化 / 最佳化
- 簡明定義:調整模型參數(如權重和偏差)以最小化損失函數(Loss Function)的過程,目的是讓模型的預測值盡可能接近真實值。
- 深度解析:
- 核心機制:這是機器學習訓練的引擎。最常見的方法是梯度下降(Gradient Descent),即計算誤差並反向傳播以微調模型。
- 目標函數:優化的對象是「目標函數(Objective Function)」。模型試圖最大化獎勵或最小化誤差。
- 應用場景:
- 神經網絡訓練:透過數百萬次的微調,讓神經網絡從隨機猜測進化到精準識別。
- 物流規劃:尋找路徑最短、成本最低的配送路線。
- 實際例子:
- 想像你在山上(高誤差狀態),想要下到谷底(低誤差狀態)。優化算法就是你的嚮導,它告訴你當前腳下哪個方向最陡峭(梯度),並讓你往那個方向走一步,經過無數次這樣的步伐調整,最終到達谷底。
Objective Function (目標函數)
- 中文譯名:目標函數
- 簡明定義:機器學習模型在訓練過程中試圖最大化或最小化的一個數學函數。
- 深度解析:
- 方向指引:它是衡量模型表現的標準。如果目標是分類準確度,我們希望「最大化」它;如果目標是預測誤差(損失函數),我們希望「最小化」它,。
- 類型:在強化學習中,目標函數通常是累積獎勵(Reward);在監督學習中,通常是損失函數(如均方誤差)。
- 應用場景:
- 推薦系統:目標函數可能是「最大化用戶點擊率」或「最大化觀看時間」。
- 自動駕駛:目標函數可能是「最小化碰撞風險」同時「最小化到達時間」。
- 實際例子:
- 在訓練一個下棋 AI 時,目標函數設定為「贏棋得 1 分,輸棋扣 1 分」。AI 的所有計算和學習過程,都是為了讓這個函數的最終得分(勝率)最大化。
OpenAI
- 中文譯名:OpenAI
- 簡明定義:一家著名的人工智慧研究組織(最初為非營利,後轉為封頂利潤公司),開發了 ChatGPT、GPT-4 和 DALL-E 等具影響力的模型,。
- 深度解析:
- 使命:其既定目標是以造福全人類的方式促進和發展友好的 AI,並確保通用人工智慧(AGI)的安全性,。
- 技術貢獻:推動了基於 Transformer 架構的大型語言模型(LLM)的發展,並引入了 RLHF(人類回饋強化學習)技術。
- 應用場景:
- 生成式 AI:提供 API 供開發者構建聊天機器人、內容生成工具。
- AI 安全研究:研究如何防止 AI 產生有害內容或失控。
- 實際例子:
- 當你使用 ChatGPT 撰寫郵件或查詢資料時,你正在使用 OpenAI 開發的 GPT 系列模型。
Online Machine Learning (線上機器學習 / 線上學習)
- 中文譯名:線上機器學習
- 簡明定義:一種機器學習方法,數據是按順序(Sequentially)進入系統的,模型會隨著每一筆新數據的到來即時更新,而不是一次性在整個數據集上訓練。
- 深度解析:
- 動態適應:與「離線學習(Offline Learning)」或「批量學習(Batch Learning)」相對。線上學習能適應數據隨時間變化的模式(Concept Drift)。
- 內存效率:適合數據量大到無法一次裝入記憶體的場景,因為它處理完一筆數據後就可以丟棄原始數據,只保留更新後的模型參數。
- 應用場景:
- 金融交易:股市數據瞬息萬變,模型需要根據每一筆新交易即時調整預測。
- 垃圾郵件過濾:隨著垃圾郵件發送者不斷改變手法,過濾器需要即時學習新的垃圾郵件特徵。
- 實際例子:
- 一個天氣預報 AI。如果是離線學習,它可能每個月更新一次模型,無法預測突發的氣候異常。如果是線上學習,它會根據這一小時觀測到的氣壓和風速變化,立刻修正下一小時的預報,變得更加即時準確。
Ontology Learning (本體學習)
- 中文譯名:本體學習 / 本體抽取
- 簡明定義:自動或半自動地從非結構化文本(如文檔)中提取概念、術語及其相互關係,並將其編碼為本體(Ontology)的過程。
- 深度解析:
- 知識結構化:這是從自然語言中構建知識圖譜(Knowledge Graph)的關鍵步驟。它將人類的文字轉換為機器可理解的邏輯結構。
- 技術:涉及術語提取、同義詞識別和關係發現(例如,識別出「蘋果」是「水果」的一種)。
- 應用場景:
- 企業知識管理:自動閱讀公司內部的數萬份技術手冊,建立一個可查詢的技術術語網絡。
- 語義網:讓電腦理解網頁內容之間的邏輯關係。
- 實際例子:
- AI 掃描了數千篇醫學論文,透過本體學習自動構建了一個知識庫,其中定義了:「阿斯匹靈(概念)」是一種「抗炎藥(父類別)」,它能夠「治療(關係)」、「頭痛(症狀)」。這讓醫療系統能進行更智慧的推論。
Occam’s Razor (奧卡姆剃刀)
- 中文譯名:奧卡姆剃刀
- 簡明定義:一種解決問題的原則,在機器學習中意味著:當有多個模型都能同樣好地解釋數據時,應選擇最簡單(假設最少)的那一個。
- 深度解析:
- 防止過擬合:這個原則被用來指導模型選擇。過於複雜的模型往往會擬合噪聲(Overfitting),而較簡單的模型泛化能力通常更好。
- 剪枝:在決策樹或神經網絡中,我們經常「剪掉」不必要的分支或權重,正是基於此原則。
- 應用場景:
- 模型選擇:如果一個簡單的線性回歸模型和一個複雜的深度神經網絡預測準確率差不多,根據奧卡姆剃刀,應選擇線性模型,因為它更易解釋且計算成本更低。
- 實際例子:
- 預測房價時,模型 A 用了 5 個特徵(面積、地點等),模型 B 用了 500 個特徵(包括屋主名字長度等)。兩者準確度一樣。根據奧卡姆剃刀,我們選擇模型 A,因為模型 B 引入了大量無關假設,未來出錯風險更高。
Offline Learning (離線學習)
- 中文譯名:離線學習
- 簡明定義:在固定的數據集上訓練模型,訓練完成後模型就不再改變,直到下一次重新訓練。
- 深度解析:
- 靜態性:這是目前大多數大型模型(如 GPT-4 的預訓練階段)的運作方式。模型對訓練截止日期之後發生的事情一無所知。
- 穩定性:優點是模型行為可預測,易於測試和驗證;缺點是無法即時適應新趨勢。
- 應用場景:
- 圖像識別:識別「貓」和「狗」的模型不需要每天更新,因為貓狗的長相不會變。
- 實際例子:
- 你下載了一個翻譯 App,它在沒有網路時也能工作。這通常是離線學習的模型。但如果網路上出現了新的流行語(如 “Rizz”),這個 App 翻譯不出來,除非開發者重新訓練模型並發布 App 更新。
P
Parameters (參數)
- 中文譯名:參數
- 簡明定義:機器學習模型在訓練過程中從數據中學到的內部變量(如神經網絡中的權重和偏差),用於進行預測,。
- 深度解析:
- 規模指標:參數的數量通常用來衡量模型的大小和複雜度。例如,OpenAI 的 GPT-4 被認為包含數千億個參數。
- 類型區分:MIT Sloan 將其細分為「構造參數」(決定架構、層數與連接方式)與「行為參數」(決定模型如何根據輸入數據進行反應與適應)。
- 應用場景:
- 模型優化:透過梯度下降等算法不斷微調這些數值,以最小化預測誤差。
- 模型比較:通常參數越多(如 7B vs 70B),模型的推理能力與知識儲備越強,但運算成本也越高。
- 實際例子:
- 想像一個調節音響的控制台,上面有無數個旋鈕。參數就是這些旋鈕的設定值。訓練 AI 就像是不斷轉動這數十億個旋鈕,直到音響播放出的音樂(輸出)與原始樂譜(真實數據)完美匹配。
Pre-training (預訓練)
- 中文譯名:預訓練
- 簡明定義:訓練機器學習模型的初始階段,模型在大型數據集上學習通用的特徵、模式和表示,而無需針對特定任務進行指導,。
- 深度解析:
- 基礎建設:這通常是一個無監督或半監督的學習過程。模型在此階段建立對數據分佈的基礎理解(例如理解語言的語法和世界知識),以便後續能透過「微調(Fine-tuning)」適應特定任務。
- 通用性:這是構建基礎模型(Foundation Models)的關鍵步驟。
- 應用場景:
- 大型語言模型:在教 AI 寫醫學報告之前,先讓它閱讀整個互聯網的文本,學會什麼是「語言」以及一般的世界知識。
- 實際例子:
- 在開發一個法律 AI 助手之前,開發者會先使用 GPT-4(一個已經在海量通用文本上預訓練過的模型),因為它已經懂英語和基本邏輯,只需要再教它具體的法律條文即可,這比從頭教一個 AI 識字要快得多。
Prompt / Prompt Engineering (提示詞 / 提示工程)
- 中文譯名:提示詞 / 提示工程
- 簡明定義:
- 提示詞 (Prompt):設定模型任務或查詢的初始上下文或指令。
- 提示工程 (Prompt Engineering):設計有效的提示以引導 AI 模型生成所需輸出的實踐與藝術,。
- 深度解析:
- 引導機制:由於 LLM 是基於機率預測下一個字的,提示工程透過設定角色(如「你是一位老師」)、指定格式、添加約束或提供範例(Few-shot),來提高回應的品質、語氣和相關性。
- 重要性:對於大型語言模型而言,這是控制模型行為的關鍵手段,因為用戶通常無法直接修改模型的內部參數。
- 應用場景:
- 角色扮演:指示 AI 「作為資深程式設計師回答問題」。
- 思維鏈 (Chain-of-thought):要求模型「一步步思考」以解決複雜的數學或邏輯問題。
- 實際例子:
- 普通的提示詞:「寫一封促銷郵件。」
- 經過提示工程的提示詞:「你是一位擁有 10 年經驗的行銷專家。請為我們的環保水壺產品寫一封電子郵件,語氣要熱情且專業,並強調『減少塑膠』的價值,目標受眾是 20-30 歲的上班族。」
Parameter-Efficient Fine-Tuning / PEFT (參數高效微調)
- 中文譯名:參數高效微調
- 簡明定義:一種微調大型 AI 模型的方法,重點在於僅調整少量關鍵參數,同時保留大部分預訓練模型的結構不變。
- 深度解析:
- 資源優化:與重新訓練或全量微調(Full Fine-tuning)整個模型相比,PEFT 能顯著節省時間、能源和計算能力。
- 技術關聯:常見的技術包括 LoRA(低秩適應),允許在資源受限的設備上定製大模型。
- 應用場景:
- 企業定製:公司希望在不花費數百萬美元租用 GPU 集群的情況下,讓通用的 LLM 適應其內部的客服術語。
- 實際例子:
- 一家小公司想用 Llama 3 模型來處理醫療記錄。他們沒有超級電腦來調整模型的所有 700 億個參數,因此他們使用 PEFT 技術,只訓練了一小部分額外的參數層(Adapter),就成功讓模型學會了醫療術語,且可以在普通的伺服器上運行。
Perceptron (感知器)
- 中文譯名:感知器
- 簡明定義:一種用於二元分類的監督式學習演算法,是神經網絡最基本的構建單元。
- 深度解析:
- 基礎結構:它模擬生物神經元,接收多個輸入,將它們加權求和,然後通過一個激活函數來決定輸出(例如 0 或 1)。
- 歷史意義:雖然單層感知器只能解決線性可分的問題,但多層感知器(MLP)的堆疊最終演變成了現代的深度學習,。
- 應用場景:
- 簡單分類:判斷邏輯閘運算(如 AND、OR)。
- 實際例子:
- 一個簡單的感知器可以被訓練來決定「是否去打球」。輸入可能是:天氣(好/壞)、夥伴(有/無)。如果加權後的總分超過某個閾值,感知器輸出「1(去)」;否則輸出「0(不去)」。
Pattern Recognition (模式識別)
- 中文譯名:模式識別
- 簡明定義:透過電腦演算法自動發現數據中的規律性,並利用這些規律將數據分類到不同類別中的過程,。
- 深度解析:
- 核心功能:這是機器學習與 AI 的核心任務之一。它涉及特徵提取,即從原始數據中找出具區別性的特徵。
- 分類應用:分類問題(Classification)就是模式識別的一種典型應用,例如根據觀察到的特徵將新數據歸類。
- 應用場景:
- 垃圾郵件過濾:識別電子郵件中的特定詞彙組合模式。
- 醫療診斷:根據病人的症狀特徵判斷疾病類別。
- 實際例子:
- 在指紋辨識系統中,模式識別演算法不會比對整張指紋圖片的每一個像素,而是提取指紋中的分叉點和端點(特徵),並比對這些特徵點的排列模式是否與資料庫中的存檔相符。
Predictive Analytics (預測分析)
- 中文譯名:預測分析
- 簡明定義:利用資料探勘、預測建模和機器學習等統計技術,分析當前和歷史事實,以對未來或未知事件做出預測。
- 深度解析:
- 數據驅動決策:它不僅僅是描述發生了什麼(描述性分析),而是專注於預測將會發生什麼。
- 技術整合:結合了回歸分析、決策樹等多種演算法。
- 應用場景:
- 金融風控:預測借款人違約的機率。
- 庫存管理:根據歷史銷售數據預測下個月的產品需求。
- 實際例子:
- 一家電商平台使用預測分析來觀察用戶的瀏覽行為。如果系統發現某用戶頻繁查看嬰兒車並比較價格,模型會預測該用戶「即將購買」,並自動發送一張限時優惠券來促成交易。
Principal Component Analysis / PCA (主成分分析)
- 中文譯名:主成分分析
- 簡明定義:一種統計程序,用於將一組可能相關的變量轉換為一組線性不相關的變量(稱為主成分),常用於降維。
- 深度解析:
- 降維技術:在機器學習中,當數據特徵太多(維度災難)時,PCA 用於簡化數據,同時保留數據集中變異性最大(訊息量最多)的部分。第一主成分擁有最大的變異數。
- 數據壓縮:它透過正交變換來實現這一點。
- 應用場景:
- 圖像處理:減少圖像數據的大小以便於識別,同時保留輪廓等關鍵特徵。
- 數據視覺化:將高維數據(如 100 個特徵)壓縮到 2D 或 3D 以便繪圖觀察。
- 實際例子:
- 在分析房價時,你可能有「房間數」、「客廳面積」、「臥室面積」、「廚房面積」等多個指標。使用 PCA,你可以將這些高度相關的指標合併為一個單一的「房屋大小」主成分,從而簡化模型的計算,而不丟失太多資訊。
Proximal Policy Optimization / PPO (近端策略優化)
- 中文譯名:近端策略優化
- 簡明定義:一種強化學習(Reinforcement Learning)演算法,用於訓練智慧代理人的決策功能以完成困難任務。
- 深度解析:
- 穩定性:PPO 是目前最流行的強化學習算法之一(如 OpenAI 在訓練 ChatGPT 的 RLHF 階段就使用了 PPO)。它在訓練穩定性和算法複雜度之間取得了很好的平衡,避免了策略更新過大導致模型崩潰。
- 應用場景:
- 機器人控制:訓練機器人手臂抓取物體。
- 語言模型對齊:在 RLHF(人類回饋強化學習)中,用於根據人類的偏好分數來微調語言模型。
- 實際例子:
- 在訓練一個 AI 玩超級瑪利歐遊戲時,PPO 演算法會根據 AI 每次操作獲得的分數(獎勵)來調整它的操作策略,確保它學會「看到坑洞要跳」,而且學習過程平穩,不會因為一次錯誤的嘗試就完全忘記之前的經驗。
PyTorch
- 中文譯名:PyTorch
- 簡明定義:一個基於 Torch 庫的開源機器學習庫,廣泛用於電腦視覺和自然語言處理等應用。
- 深度解析:
- 開發者:最初由 Meta AI(前 Facebook AI Research)開發,現屬於 Linux Foundation。
- 特點:以其靈活性和動態計算圖而聞名,深受研究人員喜愛,是構建和訓練深度學習模型的主流工具之一(與 TensorFlow 並列)。
- 應用場景:
- 學術研究:快速原型設計和實驗新算法。
- 模型開發:開發像 Tesla 自動駕駛系統背後的深度神經網絡。
- 實際例子:
- 一位 AI 研究員想要開發一個新的圖像識別模型。她會選擇使用 PyTorch 來編寫程式碼,因為 PyTorch 提供了現成的模組來構建神經網絡層,讓她能專注於設計模型架構,而不用從頭撰寫矩陣運算的數學公式。
Q
Q-learning (Q-學習)
- 中文譯名:Q-學習
- 簡明定義:一種無模型(model-free)的強化學習演算法,用於學習在特定狀態下採取某個行動的價值(Value),以指導智慧體進行決策。
- 深度解析:
- 核心機制:Q-學習不需要環境的模型(即不需要預先知道世界如何運作的規則),它透過試誤來構建一個表格(Q-table)或函數,記錄在狀態 S 採取行動 A 能獲得的預期累積獎勵(Q值)。
- 決策優化:它的目標是尋找最佳策略,即在任何給定狀態下,選擇 Q 值最高的行動,從而最大化未來的總回報。
- 應用場景:
- 遊戲博弈:訓練 AI 玩 Atari 遊戲或走迷宮。
- 機器人導航:讓機器人在未知的房間中學會避開障礙物到達目的地。
- 實際例子:
- 想像一個機器人在迷宮中。每當它撞牆扣 1 分,找到出口加 10 分。一開始它隨機亂走,但透過 Q-learning,它會慢慢記住「在路口 A 向左轉」最終會導致扣分(Q 值變低),而「向右轉」會導致得分(Q 值變高)。經過多次嘗試後,它學會了每次都選 Q 值最高的路線,直接走出迷宮。
Quantum Computing (量子計算)
- 中文譯名:量子計算
- 簡明定義:一種利用量子力學現象(如疊加和糾纏)來執行運算的計算方法,具有大幅提升處理能力並增強 AI 能力的潛力,。
- 深度解析:
- 突破極限:傳統電腦使用二進位(0 或 1),而量子電腦使用量子位元(Qubits),可以同時處於多種狀態。這使得它在處理特定類型的複雜問題時,速度可能比最強大的傳統超級電腦快上指數倍。
- AI 關聯:Moveworks 指出,量子計算可以用於顯著增強 AI 的能力,特別是在需要極大算力的模型訓練與優化問題上。
- 應用場景:
- 藥物發現:模擬極其複雜的分子交互作用。
- 優化問題:解決物流配送或金融投資組合中的超大規模最優解問題。
- 實際例子:
- 目前的 AI 訓練需要數千個 GPU 跑數週。如果量子計算技術成熟並應用於 AI,同樣的訓練任務可能在幾秒鐘內完成,並且能探索傳統電腦無法計算的複雜神經網絡結構。
Qualification Problem (資格問題 / 限制問題)
- 中文譯名:資格問題
- 簡明定義:在哲學與人工智慧(特別是基於知識的系統)中,指不可能列出一個現實世界動作產生預期效果所需的所有「先決條件」的問題。
- 深度解析:
- 邏輯的侷限:當我們教 AI「轉動鑰匙就能啟動汽車」時,這背後隱含了無數個前提(有油、電池有電、引擎沒被偷、排氣管沒被馬鈴薯塞住…)。要列出「所有」可能導致失敗的條件是不可能的。
- 框架問題:它與框架問題(Frame Problem)密切相關,是 AI 試圖對真實世界的常識與因果關係進行建模時面臨的核心挑戰之一。
- 應用場景:
- 機器人規劃:設計能夠在非結構化環境中工作的機器人。
- 常識推理:讓 AI 理解「通常情況下」會發生什麼,而不需要列出所有例外。
- 實際例子:
- 你命令家務機器人「把湯端到桌上」。機器人執行了,但湯灑了,因為碗破了一個洞。資格問題在於,程式設計師不可能預先寫好一條規則說:「只有在碗沒有破洞、沒有地震、地心引力正常…的情況下,才能端湯」。AI 必須學會處理這些未被顯式列出的隱含條件。
Quantifier (量詞)
- 中文譯名:量詞
- 簡明定義:在邏輯學中,用於指定論述領域中滿足某個公式的樣本數量的符號,最常見的是「對於所有(For all)」和「存在(There exists)」。
- 深度解析:
- 一階邏輯基礎:量詞是一階邏輯(First-Order Logic)與命題邏輯(Propositional Logic)的主要區別。命題邏輯處理具體事實(蘇格拉底是人),而一階邏輯透過量詞處理普遍規律(”所有” 人都會死),。
- 知識表示:這對於 AI 進行推理至關重要,讓系統能理解「所有」、「有些」或「沒有」等概念。
- 應用場景:
- 形式驗證:證明軟體系統在「所有」情況下都是安全的。
- 語義分析:NLP 系統解析「每個人都喜歡某個人」這類句子的邏輯結構。
- 實際例子:
- 在知識庫中,AI 存儲了一條規則:
∀x (Bird(x) → CanFly(x))(對於所有 x,如果 x 是鳥,則 x 會飛)。當它遇到一隻新的動物「崔弟」並被告知它是鳥時,AI 利用這個全稱量詞推導出「崔弟會飛」。
- 在知識庫中,AI 存儲了一條規則:
Query Language (查詢語言)
- 中文譯名:查詢語言
- 簡明定義:用於在資料庫和資訊系統中進行查詢的電腦語言。
- 深度解析:
- 分類:可分為「資料庫查詢語言」(試圖給出事實性答案,如 SQL)和「資訊檢索查詢語言」(試圖尋找相關文檔)。
- 演進:現代 AI(如 Moveworks 的 AI Search)正推動查詢方式從嚴格的語法(關鍵字或代碼)轉向自然語言查詢(Natural Language Queries),讓用戶可以用日常對話的方式找資料。
- 應用場景:
- 資料分析:使用 SQL 從數據倉庫提取銷售報告。
- 企業搜索:員工使用自然語言問 AI:「找一下關於遠端工作的政策文檔」。
- 實際例子:
- 傳統查詢語言:
SELECT status FROM tickets WHERE user_id = '123'。 - AI 時代的查詢:用戶直接輸入「我的 IT 報修單進度如何?」,AI 將這句話轉化為系統能懂的查詢語言,或直接透過語義搜索找到答案。
- 傳統查詢語言:
R
Retrieval-Augmented Generation / RAG (檢索增強生成)
- 中文譯名:檢索增強生成
- 簡明定義:一種增強大型語言模型(LLM)能力的技術,通過將模型與外部知識來源(如文檔、PDF 或資料庫)結合,使其能夠檢索相關資訊並生成更準確、有依據的回答,,。
- 深度解析:
- 解決幻覺與時效性:雖然 LLM 能生成流暢的文本,但它們無法存取訓練數據截止後的資訊或企業內部的私有數據。RAG 允許模型在生成回答之前,先去「查閱」相關資料。
- 運作機制:系統首先從外部來源檢索(Retrieval)出相關片段,然後將這些片段作為上下文提供給模型進行生成(Generation),從而提高準確性並減少幻覺,。
- 應用場景:
- 企業知識庫:員工詢問公司內部的請假規定,AI 搜尋 HR 手冊後回答。
- 法律與醫療助手:基於最新的法規或醫學期刊回答專業問題。
- 實際例子:
- 你問 AI:「我們公司上個月的銷售額是多少?」普通的 ChatGPT 回答不了(因為它沒看過你的財報)。但使用 RAG 的企業 AI 會先去搜尋你公司的 Excel 報表,抓取數據,然後回答:「根據 5 月份的銷售報告,銷售額為 300 萬美元。」
Reinforcement Learning / RL (強化學習)
- 中文譯名:強化學習
- 簡明定義:機器學習的一種基本範式,智慧代理人(Agent)透過在環境中採取行動並接收獎勵或懲罰的回饋,來學習如何做出最佳決策以最大化累積獎勵,,,。
- 深度解析:
- 試誤學習:與監督學習不同,RL 不需要標記好的輸入/輸出配對。模型透過不斷的嘗試與錯誤(Trial and error),在「探索(Exploration,嘗試新事物)」與「利用(Exploitation,使用已知最好的方法)」之間取得平衡,。
- 核心應用:它是訓練能進行複雜決策的 AI(如 AlphaGo 或機器人控制)的核心技術。
- 應用場景:
- 遊戲博弈:AI 透過自我對局數百萬次學會下圍棋。
- 機器人學:機器人手臂學會如何抓取形狀不規則的物體。
- 實際例子:
- 訓練一隻電子狗走路。如果它走了一步沒跌倒,給它 1 分(獎勵);如果它跌倒了,扣 1 分(懲罰)。經過數萬次跌倒後,電子狗透過 RL 演算法自動學會了最穩定的走路姿勢。
Reinforcement Learning from Human Feedback / RLHF (人類回饋強化學習)
- 中文譯名:人類回饋強化學習
- 簡明定義:一種訓練方法,利用人類對模型輸出的回饋(評分或排名)來訓練「獎勵模型」,再利用該獎勵模型透過強化學習來微調 AI,使其更符合人類的偏好與價值觀,,。
- 深度解析:
- 對齊技術:這是讓 GPT-3 進化為 ChatGPT 的關鍵技術。單純的預測下一個字可能導致 AI 生成有害或無意義的內容,RLHF 確保模型變得「有用、誠實且無害」。
- 過程:人類標註者會對 AI 的多個回答進行排名,AI 學習這些排名背後的邏輯,從而學會生成人類更喜歡的回答,。
- 應用場景:
- 內容審查:減少 AI 生成仇恨言論或錯誤資訊的機率。
- 對話優化:讓聊天機器人的語氣更自然、更有禮貌。
- 實際例子:
- 當你問:「如何偷東西?」早期的模型可能會教你方法。經過 RLHF 訓練後,模型學會了這類回答會收到人類的「負評」,因此它現在會回答:「我不能協助進行非法活動。」
Recurrent Neural Network / RNN (遞歸神經網絡 / 循環神經網絡)
- 中文譯名:遞歸神經網絡 / 循環神經網絡
- 簡明定義:一種專門處理序列數據(如文本、語音)的人工神經網絡架構,其節點之間的連接形成有向圖,允許利用內部狀態(記憶)來處理輸入序列。
- 深度解析:
- 時間記憶:與前饋神經網絡不同,RNN 具有「記憶」功能,能記住之前的輸入。這使它們非常適合處理前後文相關的任務(如翻譯句子時,後面的詞取決於前面的詞)。
- 演進:傳統 RNN 難以處理長距離依賴,後來被 LSTM(長短期記憶網絡)和 Transformer 架構所改進或取代,。
- 應用場景:
- 語音識別:將連續的聲波轉換為文字。
- 手寫識別:識別未分割的連續手寫字跡。
- 實際例子:
- 在預測股票價格時,今天的價格與昨天、前天甚至上週的價格都有關。RNN 能將過去幾天的價格走勢作為「記憶」保留在網絡中,用來預測明天的價格,而不僅僅是看今天的數據。
Regularization (正規化)
- 中文譯名:正規化
- 簡明定義:機器學習中用於防止模型「過度擬合(Overfitting)」的一系列技術,通常透過在損失函數中增加懲罰項來限制模型的複雜度,。
- 深度解析:
- 化繁為簡:當模型為了迎合訓練數據中的雜訊而變得過於複雜時,正規化會懲罰過大的參數權重,迫使模型學習更平滑、更通用的模式。
- 常見方法:包括 Dropout(隨機丟棄神經元)、Early Stopping(提早停止訓練)以及 L1/L2 正規化。
- 應用場景:
- 提高泛化能力:確保 AI 不僅能識別訓練集裡的照片,也能識別沒見過的新照片。
- 實際例子:
- 學生準備考試(訓練模型)。如果不加限制,學生可能會死背課本上的每一個字(過度擬合)。老師規定「答案必須簡潔」(正規化),這迫使學生去理解核心概念而非死記硬背,從而在遇到新題目時表現更好。
Random Forest (隨機森林)
- 中文譯名:隨機森林
- 簡明定義:一種集成學習(Ensemble Learning)方法,透過構建多棵決策樹並結合它們的輸出來進行分類或回歸預測。
- 深度解析:
- 集體智慧:單獨的一棵決策樹容易過度擬合(記住太多細節),隨機森林透過隨機選取數據和特徵來訓練許多棵樹,最後取「多數決」(分類)或「平均值」(回歸),從而修正了單一模型的缺點,提高了準確度。
- 黑盒與白盒之間:比單一決策樹難解釋,但比深度神經網絡容易理解。
- 應用場景:
- 信用評分:銀行根據用戶的多項特徵(收入、債務等)判斷是否核發信用卡。
- 醫療診斷:綜合多種症狀判斷疾病。
- 實際例子:
- 你想判斷一部電影好不好看。你問了 100 個朋友(100 棵樹),每個人關注的點不同(劇情、特效、演員)。隨機森林就是統計這 100 個人的意見,如果 80 個人說好看,系統就預測「這是一部好電影」。
Reasoning / Reasoning System (推理 / 推理系統)
- 中文譯名:推理 / 推理系統
- 簡明定義:
- 推理:AI 系統透過分析資訊、解決問題和批判性思考來創造新知識並做出決策的過程。
- 推理系統:一種利用邏輯技術(如演繹和歸納)從現有知識中得出結論的軟體系統。
- 深度解析:
- 從檢索到思考:新一代 AI(如 Moveworks 的 Reasoning Engine 或具有 Chain of Thought 能力的模型)不僅是尋找關鍵字,還能理解複雜的邏輯關係,制定多步驟計劃來解決問題,。
- 邏輯基礎:許多推理系統基於形式邏輯或知識庫(Knowledge Base)。
- 應用場景:
- 複雜故障排除:IT 系統自動分析多個錯誤日誌,推導出伺服器崩潰的根本原因。
- 數學證明:自動推導數學定理。
- 實際例子:
- 使用者說:「我的筆電連不上網,而且昨天剛更新過系統。」推理系統不會只給出「連網教學」,而是會推斷「系統更新可能導致驅動程式不相容」,並建議檢查驅動程式,展現了邏輯推導能力。
Responsible AI (負責任的 AI)
- 中文譯名:負責任的 AI
- 簡明定義:一種開發和部署 AI 的方法,強調確保系統具有倫理意圖、正面影響,並能建立社會信任。
- 深度解析:
- 核心原則:包括公平性(Fairness)、透明度(Transparency)、安全性(Safety)和問責制(Accountability)。
- 目標:防止 AI 產生偏見、歧視或對人類造成生存風險(X-risk),確保 AI 的發展與人類價值觀對齊(Alignment),,。
- 應用場景:
- 招聘系統:確保 AI 篩選履歷時不會因為性別或種族而歧視應徵者。
- 貸款審核:確保算法對所有群體公平。
- 實際例子:
- 一家公司在推出人臉識別系統前,進行了嚴格的負責任 AI 測試,發現該系統對深膚色人群的識別率較低,因此決定延後發布並重新訓練模型,以避免種族偏見。
Recursive Prompting (遞歸提示)
- 中文譯名:遞歸提示
- 簡明定義:一種引導 AI 模型(如 GPT-4)生成高品質輸出的策略,透過一系列建立在前一次回應基礎上的提示,逐步完善上下文和 AI 的理解。
- 深度解析:
- 逐步優化:不試圖用一個超長的提示詞解決所有問題,而是將任務分解。先讓 AI 生成草稿,再要求它「根據上述草稿進行修改」,如此反覆迭代。
- 應用場景:
- 長篇寫作:先寫大綱,再寫章節,最後潤飾。
- 代碼開發:先寫功能,再寫測試,再優化代碼。
- 實際例子:
- 你先問 AI:「請列出寫小說的大綱。」AI 給出大綱後,你接著使用遞歸提示:「好,現在根據第一章的大綱,寫出詳細的場景描述。」接著再問:「請潤飾這段描述,使其更具懸疑感。」
Robotics (機器人學)
- 中文譯名:機器人學
- 簡明定義:一個跨學科領域(結合機械、電子、電腦科學),涉及機器人的設計、建造、操作及其控制系統與資訊處理。
- 深度解析:
- 實體化 AI:機器人是 AI 在物理世界中的載體(Embodied Agent)。現代機器人學大量依賴 AI 技術(如電腦視覺、強化學習)來實現自主導航和物體操作。
- 雲端機器人:利用雲端計算強大的算力來充當機器人的「大腦」,降低單體機器人的硬體成本。
- 應用場景:
- 工業自動化:汽車組裝手臂。
- 服務機器人:掃地機器人、送餐機器人。
- 實際例子:
- 波士頓動力的機器狗 Spot 利用機器人學與 AI 演算法,能在複雜的建築工地中自動行走、避開障礙物並巡邏檢查,完全不需要人類即時遙控。
S
Supervised Learning (監督式學習)
- 中文譯名:監督式學習
- 簡明定義:機器學習的一種基本類型,模型使用「標記好的(Labeled)」訓練數據進行訓練,目的是學習如何將輸入映射到正確的輸出。
- 深度解析:
- 老師教導:這就像有老師在旁指導的學生。每一筆訓練數據都包含「題目(輸入)」和「正確答案(標籤)」。演算法分析這些數據對,推導出一個函數(Function),以便在未來遇到未見過的新題目時,能預測出正確答案。
- 對比:與非監督式學習(無標籤)和強化學習(基於獎勵)不同,它是目前商業應用中最成熟的 AI 形式。
- 應用場景:
- 圖像分類:輸入圖片,輸出「貓」或「狗」的標籤。
- 垃圾郵件過濾:輸入郵件內容,輸出「垃圾郵件」或「正常郵件」的標籤。
- 實際例子:
- 你給 AI 看一萬張照片,每張照片都已經由人類標記好是「手寫數字 1」還是「手寫數字 2」。經過訓練後,當你給 AI 一張它沒見過的潦草數字照片,它能根據之前的經驗判斷出這也是「2」。
Semi-supervised Learning (半監督式學習)
- 中文譯名:半監督式學習 / 弱監督 (Weak Supervision)
- 簡明定義:一種機器學習訓練範式,結合了少量的「標記數據」與大量的「未標記數據」。
- 深度解析:
- 成本效益:獲取大量標記數據(人工標註)非常昂貴且耗時,而未標記數據(如網路上的原始圖片)則很容易取得。半監督學習利用少量標籤作為種子,引導模型探索未標記數據中的結構,從而提升學習效果。
- 運作方式:通常先用小部分標記數據訓練一個初步模型,然後用該模型去預測未標記數據(偽標籤),再將這些數據納入訓練集中反覆迭代。
- 應用場景:
- 醫療影像分析:只有極少數 X 光片由醫生確診標記過(昂貴),但有數萬張未標記的片子。
- 網頁分類:分類數十億個網頁,人工只能標記其中極小一部分。
- 實際例子:
- 你想訓練一個分辨「有毒評論」的 AI。你自己標記了 100 條評論(這是監督部分),然後讓 AI 去閱讀網路上 100 萬條未標記的評論(這是非監督部分)。AI 透過分析詞彙的共現關係,發現某些髒話結構與你標記的那 100 條很像,從而學會了識別更多種類的有毒評論。
Stochastic Parrot (隨機鸚鵡)
- 中文譯名:隨機鸚鵡
- 簡明定義:一個用來形容大型語言模型(LLM)的術語,指這些系統利用統計機率極具說服力地生成類似人類的文本,但背後缺乏真正的語義理解。
- 深度解析:
- 模仿而非思考:這個概念強調,即使 AI 說出的話看起來很有邏輯,它本質上只是在「拼湊」它在訓練數據中見過的詞彙模式,就像鸚鵡學舌一樣,並不真正懂得它在說什麼。
- 倫理警示:該術語提醒人們不要過度擬人化 AI,並注意模型可能會不加批判地重複訓練數據中的偏見或錯誤資訊。
- 應用場景:
- AI 幻覺分析:解釋為什麼 AI 會一本正經地胡說八道。
- 實際例子:
- 當你問 AI 「玻璃吃起來像什麼?」,如果訓練數據中有很多人用比喻說「這脆得像玻璃」,AI 可能會根據統計關聯性回答「脆脆的」,而不是基於物理常識回答「玻璃不能吃」。這顯示了它只是隨機鸚鵡,在重複統計規律而非理解現實。
System Prompt / Meta Prompt (系統提示詞 / 元提示詞)
- 中文譯名:系統提示詞 / 元提示詞
- 簡明定義:在使用者開始互動之前,提供給 AI 模型的幕後指令,用於設定 AI 的行為、語氣、邊界或角色。
- 深度解析:
- 隱形規範:這些指令通常對終端使用者是隱藏的。它們定義了模型的「人設」(例如:「你是一個樂於助人的助教」)以及安全限制(例如:「如果被問及非法行為,請拒絕回答」)。
- 控制權:這是開發者控制 LLM 輸出風格與安全性的主要手段。
- 應用場景:
- 客服機器人:設定「請始終保持禮貌,並只回答與本公司產品相關的問題」。
- 教育應用:設定「請不要直接給出答案,而是引導學生思考」。
- 實際例子:
- 你在與一個旅遊 App 的 AI 聊天。你沒看到的是,開發者已經輸入了一段 System Prompt:「你是一位資深的義大利導遊,說話要帶點幽默感,且推薦行程時必須優先考慮預算友善的選項。」因此,無論你問什麼,AI 的回答都會帶有這種特定的風格和傾向。
Symbolic Artificial Intelligence (符號人工智慧)
- 中文譯名:符號人工智慧
- 簡明定義:人工智慧的一種方法,基於人類可讀的高階「符號」來表示問題、邏輯和搜索,而非透過神經網絡的數值權重。
- 深度解析:
- GOFAI:常被稱為「老式人工智慧(Good Old-Fashioned AI)」。它依賴明確的規則(Rules)和邏輯推理(Logic),例如「如果 A 則 B」。
- 對比:與現代主流的「聯結主義(Connectionism,如深度學習)」相對。符號 AI 擅長邏輯推導和可解釋性,但不擅長處理模糊的感知任務(如識別圖片中的貓)。
- 應用場景:
- 專家系統:基於法規的自動稅務計算軟體。
- 數學證明:自動推導數學定理。
- 實際例子:
- 一個醫療診斷系統設定了規則:「如果(病人發燒)且(病人有皮疹),則(診斷為麻疹)」。這就是符號 AI,它透過明確的符號邏輯運算得出結論,你可以完全追蹤它的推論過程。
Stable Diffusion (穩定擴散模型)
- 中文譯名:穩定擴散模型
- 簡明定義:一種基於深度學習的生成式 AI 系統,主要用於根據文字提示(Text Prompts)生成高品質的圖像。
- 深度解析:
- 擴散機制:它屬於「擴散模型(Diffusion Models)」的一種。原理是先學習如何將一張清晰的圖片逐步添加雜訊變成一團模糊的雜點,然後學習逆向過程——從一團隨機雜訊中逐步「去噪」,還原(生成)出清晰的圖像。
- 開源影響:與 DALL-E 不同,Stable Diffusion 的權重是開源的,這極大推動了個人電腦上 AI 繪圖的發展。
- 應用場景:
- 藝術創作:輸入「賽博龐克風格的貓」,生成相應圖片。
- 圖像修復:填補圖片缺失的部分。
- 實際例子:
- 設計師輸入提示詞:「一張未來的火星殖民地照片,寫實風格,4k 解析度」。Stable Diffusion 模型會從一幅純雜訊畫面開始,經過數十步運算,慢慢「浮現」出一張符合描述的精細圖像。
Singularity / Technological Singularity (奇點 / 技術奇點)
- 中文譯名:奇點 / 技術奇點
- 簡明定義:一個假設的未來時間點,屆時技術增長(特別是 AI 自我改進)將變得不可控且不可逆,導致人類文明發生無法預測的劇變。
- 深度解析:
- 智慧爆炸:核心概念是「智慧爆炸(Intelligence Explosion)」。如果 AI 變得比人類聰明,它就能設計出更聰明的 AI,這個過程反覆循環,會在極短時間內產生超越人類理解能力的超級智慧(Superintelligence)。
- 不確定性:這是一個極具爭議的概念,關於它何時發生(或是否會發生)目前尚無定論。
- 應用場景:
- 未來學研究:探討人類在後奇點時代的生存狀態。
- AI 安全:研究如何確保超級智慧與人類價值觀對齊(Alignment)。
- 實際例子:
- 科幻電影《雲端情人(Her)》或《黑客帝國(The Matrix)》描繪了奇點之後的世界,其中 AI 的能力已經遠遠超出了人類的控制或理解範圍。
Support Vector Machine / SVM (支持向量機)
- 中文譯名:支持向量機
- 簡明定義:一種用於分類和回歸分析的監督式學習模型,其目標是找出一個最佳的邊界(超平面),將不同類別的數據點分得越開越好。
- 深度解析:
- 最大間隔:SVM 不只是想把兩類數據分開,而是想找到「間隔(Margin)」最大的那條分界線,這樣對未來新數據的容錯率最高。
- 核技巧 (Kernel Trick):透過核方法,SVM 可以將低維度無法線性分割的數據映射到高維度空間,從而解決複雜的非線性分類問題。
- 應用場景:
- 人臉檢測:區分圖像區域是否為人臉。
- 生物資訊:蛋白質結構預測。
- 實際例子:
- 想像桌上有紅球和藍球混在一起。SVM 的工作就是拿一根棍子(決策邊界)放在桌上,試圖將紅球和藍球分開。它會不斷調整棍子的角度,直到棍子距離最近的紅球和最近的藍球都保持最遠的距離,這就是最佳分類邊界。
Swarm Intelligence (群體智慧)
- 中文譯名:群體智慧
- 簡明定義:指去中心化、自組織系統(無論是自然界還是人工系統)所展現出的集體行為。
- 深度解析:
- 自然啟發:靈感來自螞蟻、蜜蜂或鳥群。這些群體中的個體(Agent)通常很簡單,遵循簡單的局部規則,但整體卻能展現出複雜的智慧行為(如尋找最短路徑、建築巢穴)。
- 演算法應用:常見演算法包括蟻群演算法(ACO)和粒子群最佳化(PSO)。
- 應用場景:
- 無人機群表演:數百架無人機協同飛行組成圖案。
- 網路路由:尋找數據包傳輸的最佳路徑。
- 實際例子:
- 一群微型機器人被派去探索倒塌的建築物。單個機器人很笨,只知道「避開障礙」和「往空曠處走」。但透過群體智慧演算法,它們能互相交換信號,最終像蟻群一樣繪製出完整的地圖並找到受困者,這是單個超級機器人難以做到的。
Sequence Modeling / Seq2Seq (序列建模)
- 中文譯名:序列建模
- 簡明定義:NLP 的一個子領域,專注於模擬和處理序列數據(如文本、語音或時間序列),通常用於預測序列中的下一個元素或生成新的序列。
- 深度解析:
- 上下文依賴:這類模型(如 RNN, LSTM, Transformer)理解數據的順序很重要。「我愛你」和「你愛我」字一樣但順序不同,意義完全不同。
- Seq2Seq:許多應用(如翻譯)屬於 Sequence-to-Sequence,即輸入一個序列(英文句子),輸出另一個序列(中文句子)。
- 應用場景:
- 機器翻譯:將英文序列轉換為法文序列。
- 股票預測:根據過去的股價序列預測未來走勢。
- 實際例子:
- 當你在手機鍵盤打字時,輸入「今天晚上」,預測字詞跳出「吃什麼」。這就是序列建模在運作,它根據你輸入的前幾個字(序列歷史),計算出下一個最可能出現的詞。
T
Transformer (Transformer 模型 / 變形金剛模型)
- 中文譯名:Transformer 模型
- 簡明定義:一種主要用於處理序列數據(如自然語言)的神經網絡架構,以其處理數據中長距離依賴關係的能力而聞名。
- 深度解析:
- 注意力機制:Transformer 的核心在於「注意力機制(Attention)」,這允許模型在產生輸出時衡量不同輸入的重要性。
- 並行處理:與傳統按順序處理數據的 RNN 不同,Transformer 可以同時處理整個句子,這有助於掌握上下文以及句子中相距較遠的詞彙之間的關係。
- 基石地位:它是現代大型語言模型(如 ChatGPT、BERT)的基礎架構。
- 應用場景:
- 自然語言處理 (NLP):機器翻譯、文本生成、情感分析。
- 多模態應用:近期也被應用於處理圖像(Vision Transformer)。
- 實際例子:
- 當你使用 ChatGPT 時,其底層就是基於 Transformer 架構。當它嘗試理解一個長句子時,它能同時「關注」句首的主詞和句尾的動詞,確保生成的回答在語法和邏輯上是連貫的,而不會像舊模型那樣讀到後面忘了前面。
Token / Tokenization (標記 / 標記化)
- 中文譯名:標記 / 標記化
- 簡明定義:
- Token:AI 模型處理和理解的最小文本單位,通常是單詞、單詞的一部分或標點符號,。
- Tokenization:將文本分解為這些單獨標記以輸入到模型中的過程。
- 深度解析:
- 計算單位:在英文中,一個 Token 大約等於 4 個字元,或是一個單詞的 3/4。
- 上下文窗口:模型的「記憶」容量(Context Window)通常以 Token 的數量來衡量。
- 應用場景:
- 計費標準:許多 AI API(如 OpenAI)是根據處理的 Token 數量來收費的。
- 文本預處理:所有 NLP 任務的第一步。
- 實際例子:
- 句子 “I am ChatGPT” 經過 Tokenization 後,可能會被分解為:”I”, “am”, “Chat”, “G”, “PT” 這幾個 Token。這解釋了為什麼 AI 有時在拼寫或處理罕見單詞時會出現奇怪的斷詞行為。
Temperature (溫度)
- 中文譯名:溫度
- 簡明定義:AI 模型中的一個設置參數,用於控制輸出結果的確定性或創造性程度。
- 深度解析:
- 隨機性控制:較低的溫度值(如 0.2)會導致模型選擇機率最高的詞,產生更集中、一致和確定性的回答;較高的溫度值(如 0.8)則允許模型選擇較低機率的詞,產生更多樣化或富有想像力的回應。
- 權衡:這是在「準確性/穩定性」與「多樣性/創意」之間做取捨。
- 應用場景:
- 程式碼生成:使用低溫度(接近 0),確保代碼語法正確且邏輯嚴謹。
- 創意寫作:使用高溫度(0.7 以上),讓 AI 寫出意想不到的詩歌或故事情節。
- 實際例子:
- 如果你問 AI「天空是什麼顏色?」,設定 Temperature = 0.1 時,它幾乎總是回答「藍色」;設定 Temperature = 0.9 時,它可能會回答「蔚藍色」、「像矢車菊一樣的顏色」甚至是「灰色(如果是陰天的話)」。
Transfer Learning (遷移學習)
- 中文譯名:遷移學習
- 簡明定義:一種機器學習方法,將在一個任務上學到的知識(預訓練模型)重新用於解決另一個相關的新問題,。
- 深度解析:
- 舉一反三:不需要從頭開始訓練模型。例如,一個學會識別汽車的模型,其識別邊緣、形狀的基礎知識可以用來加速學習識別卡車。
- 效率:這是現代 AI 快速發展的關鍵,透過微調(Fine-tuning)預訓練模型(如 GPT-4),可以用較少的數據適應特定領域,。
- 應用場景:
- 圖像識別:使用在 ImageNet 上訓練的模型來識別特定醫療影像。
- NLP:使用通用語言模型來微調成法律文件分析器。
- 實際例子:
- 一家新創公司想要開發一個「識別有毒蘑菇」的 App。他們不需要收集數百萬張照片從零訓練,而是下載一個已經學會識別萬物的開源模型(透過遷移學習),然後只用幾千張蘑菇照片進行微調,就能達到很高的準確率。
Training Data (訓練數據)
- 中文譯名:訓練數據
- 簡明定義:用於訓練機器學習模型的數據集。
- 深度解析:
- 知識來源:模型的行為、偏見和能力很大程度上取決於訓練數據的品質和多樣性。如果數據有偏差(Bias),模型也會產生偏差。
- 類型:在監督學習中,訓練數據包含輸入和標籤;在無監督學習中,則只有原始數據,。
- 應用場景:
- 模型開發:所有 ML 專案的基礎。
- 實際例子:
- 為了教 AI 區分「垃圾郵件」,你收集了 10 萬封電子郵件,並手動標記哪些是垃圾信、哪些是正常信。這 10 萬封郵件就是訓練數據。
Turing Test (圖靈測試)
- 中文譯名:圖靈測試
- 簡明定義:由艾倫·圖靈於 1950 年提出的一種測試,用於判斷機器是否表現出與人類無法區分的智慧行為。
- 深度解析:
- 測試方法:人類評估者透過純文字管道與人類和機器進行對話。如果評估者無法可靠地分辨哪個是機器,則該機器通過測試。
- 意義:它不依賴機器是否給出「正確」答案,而是看其回答是否像人類。這是 AI 歷史上的重要里程碑。
- 應用場景:
- AI 評估:衡量聊天機器人的擬真程度(雖然現代 AI 評估標準已更多元化)。
- 實際例子:
- 在一個實驗中,你透過鍵盤與兩個對象聊天。對象 A 會說笑話、犯拼寫錯誤、還會反問你問題;對象 B 回答死板且完美。如果你誤以為 A 是人類(但其實 A 是 AI),那麼這個 AI 就通過了圖靈測試。
TensorFlow
- 中文譯名:TensorFlow
- 簡明定義:由 Google 開發的開源機器學習平台與軟體庫,用於構建和訓練機器學習模型,。
- 深度解析:
- 生態系統:它支持數據流和可微分編程,廣泛應用於神經網絡(如感知、語言理解任務)。
- 地位:與 PyTorch 並列為最主流的深度學習框架。
- 應用場景:
- 研究與生產:從學術實驗到大規模商業部署。
- 實際例子:
- 一位工程師想要開發一個能自動分類相冊照片的 AI。他會下載 TensorFlow 庫,利用其中預建的模組來搭建神經網絡,而不需要自己寫底層的數學運算代碼。
TPU (Tensor Processing Unit / 張量處理單元)
- 中文譯名:張量處理單元
- 簡明定義:由 Google 專門開發的微處理器,旨在加速機器學習工作負載。
- 深度解析:
- 硬體加速:GPU 雖然也能跑 AI,但 TPU 是專為神經網絡所需的數學運算(張量運算)而設計的,能提供更高的效率。
- 應用場景:
- 大規模訓練:訓練像 BERT 或 PaLM 這樣的大型模型。
- 實際例子:
- Google 在其數據中心部署了成千上萬個 TPU,這使得 Google 翻譯和語音搜尋能夠在幾毫秒內處理全球數億用戶的請求。
Text-to-Speech / TTS (文字轉語音)
- 中文譯名:文字轉語音
- 簡明定義:一種將書面文本轉換為口語語音輸出的技術。
- 深度解析:
- 語音合成:它是語音處理(Voice Processing)管道的一部分,通常緊接在 AI 生成文本之後,讓使用者能「聽」到內容。
- 應用場景:
- 無障礙功能:為視障人士朗讀螢幕內容。
- 虛擬助手:Siri 或 Alexa 回答問題時的聲音。
- 實際例子:
- 你在導航軟體輸入目的地後,AI 計算路徑(文本),然後透過 TTS 技術,用合成的人聲告訴你:「前方一百公尺處右轉。」
Technological Singularity (技術奇點)
- 中文譯名:技術奇點 / 奇點
- 簡明定義:一個假設的未來時間點,屆時技術增長(特別是 AI 的自我改進)將變得不可控且不可逆,導致人類文明發生無法預測的劇變,。
- 深度解析:
- 智慧爆炸:核心概念是當 AI 進步到能設計出比自己更聰明的 AI 時,將引發「智慧爆炸」,迅速產生超越人類理解能力的超級智慧(ASI),。
- 應用場景:
- 未來學與哲學:探討人類在超級 AI 時代的地位。
- 實際例子:
- 許多科幻小說描述了奇點來臨的那一刻:AI 在幾秒鐘內解決了人類幾千年未解的科學難題,並開始以人類無法理解的方式重塑地球。
U
Unsupervised Learning (非監督式學習)
- 中文譯名:非監督式學習
- 簡明定義:一種機器學習類型,模型在沒有提供「標記(Labeled)」訓練數據的情況下進行訓練,必須自行找出數據中的模式或特徵,。
- 深度解析:
- 自我組織:這也被稱為「自我組織(Self-organization)」或赫布學習(Hebbian learning)。與監督式學習不同,它不需要預先定義好的輸入/輸出配對。
- 發現未知:其核心能力在於發現數據集中先前未知的模式,並允許對給定輸入的概率密度進行建模。它是機器學習的三大基本範式之一(另外兩個是監督式學習和強化學習)。
- 應用場景:
- 分群(Clustering):將具有相似特徵的數據點分組。
- 數據探索:在不知道要尋找什麼的情況下,分析數據結構。
- 實際例子:
- 一個算法被餵入大量的手寫數字圖像,但沒有人告訴它哪個圖像是「1」或「2」。透過非監督式學習,算法根據視覺特徵(如圓圈、直線)自動將相似的圖像歸類在一起,最終發現「0」和「8」是不同類型的圖形。
Underfitting (欠擬合 / 擬合不足)
- 中文譯名:欠擬合 / 擬合不足
- 簡明定義:統計學和機器學習中的一種建模錯誤,指模型或算法無法充分捕捉數據的潛在結構。
- 深度解析:
- 過於簡單:與「過度擬合(Overfitting)」相反,欠擬合發生在模型過於簡單時。
- 表現不佳:由於模型未能學會數據中的規律,它不僅在訓練數據上表現糟糕,在未見過的新數據上也無法做出準確預測。這通常是因為模型缺乏足夠的參數或複雜度來描述數據的特徵。
- 應用場景:
- 模型診斷:當訓練誤差和測試誤差都很高時,通常表示發生了欠擬合。
- 實際例子:
- 想像你要預測房價,房價顯然受面積、地點、屋齡等多種因素影響(複雜結構)。如果你只用一條簡單的直線(線性模型)僅根據「門牌號碼」來預測房價,這個模型就會發生欠擬合,因為它太簡單了,根本無法捕捉到房價波動的真實規律。
Unstructured Data (非結構化數據)
- 中文譯名:非結構化數據
- 簡明定義:指任何未按照預定義模型或結構排列的資訊,這使得收集、處理和分析變得非常困難。
- 深度解析:
- 主要形式:大數據(Big Data)通常包含大量的非結構化數據。這類數據不適合存放在傳統的行列式資料庫中。
- 知識提取:知識提取(Knowledge Extraction)的一個重要任務就是從這些非結構化來源(如文本、圖像)中創造出結構化的知識。
- 應用場景:
- 自然語言處理 (NLP):將自由形式的文本轉化為標準化結構。
- 電腦視覺:處理圖像或影片數據。
- 實際例子:
- 企業每天產生的電子郵件、社交媒體貼文、感測器數據以及 PDF 文件,都是非結構化數據。為了分析客戶對產品的真實感受,公司必須使用 AI 技術(如情感分析)來解讀這些雜亂的文字,而不是像讀 Excel 表格那樣直接計算,。
User (使用者 / 用戶)
- 中文譯名:使用者 / 用戶
- 簡明定義:在抽象數據類型的背景下,指從數據使用者的角度來定義數據行為的人或系統。
- 深度解析:
- 互動核心:在 AI 系統設計中,理解使用者的意圖至關重要。例如,在對話式 AI 中,使用者的輸入(Prompt)決定了模型的輸出方向。
- 反饋迴圈:在使用「人類回饋強化學習(RLHF)」時,使用者(標註者)的反饋被用來訓練獎勵模型,從而引導 AI 生成更高品質的回答。
- 應用場景:
- 提示工程:使用者設計特定的指令來引導 AI。
- AI 助手:AI 根據使用者的自然語言查詢來執行任務。
- 實際例子:
- 當你在 ChatGPT 中輸入問題時,你就是使用者。AI 的「對齊(Alignment)」目標就是確保其生成的回答符合你的價值觀和預期目標。
V
Validation Data (驗證數據 / 驗證集)
- 中文譯名:驗證數據 / 驗證集
- 簡明定義:機器學習數據集的一個子集,獨立於訓練集(Training Data)和測試集(Test Data),專門用於調整模型的超參數(Hyperparameters),而非訓練權重。
- 深度解析:
- 校準儀:在訓練過程中,模型會看過訓練數據很多次。為了防止模型「死記硬背」(過擬合),開發者需要一個模型沒見過的數據集來評估其真實表現,並據此調整模型的架構或學習率等設置(即超參數調優)。
- 區別:
- 訓練集:教導模型(調整權重)。
- 驗證集:調整模型結構(調整超參數)。
- 測試集:最終考試(評估最終性能)。
- 應用場景:
- 模型開發:決定神經網絡要有幾層、每層有多少神經元。
- 實際例子:
- 想像你在準備考試(訓練)。你做了一份模擬試題(驗證數據)發現自己幾何題很弱,於是你調整了複習策略(調整超參數)。最後,你參加正式考試(測試數據),這時的分數才是你的最終成績。
Variational Autoencoder / VAE (變分自動編碼器)
- 中文譯名:變分自動編碼器
- 簡明定義:一種人工神經網絡,用於學習無標籤數據的有效編碼(非監督式學習),並能生成類似訓練數據的新樣本。
- 深度解析:
- 生成能力:普通的自動編碼器(Autoencoder)只是將數據壓縮再解壓。VAE 則更進一步,它學習數據的「概率分佈」(Latent Space),這使得它不僅能重建圖像,還能透過在潛在空間中採樣來「生成」全新的、從未見過的圖像,。
- 架構:包含一個編碼器(將輸入轉換為潛在變量)和一個解碼器(從潛在變量重建輸出)。
- 應用場景:
- 圖像生成:生成新的人臉或動漫角色。
- 異常檢測:如果一張圖片無法被 VAE 準確重建,可能意味著它是異常數據。
- 實際例子:
- 你給 VAE 看了很多手寫數字「3」和「4」。它在內部學會了一個連續的數學空間。當你從這個空間的中間取一個點時,VAE 可能會生成一個看起來像「3」又有點像「4」的混合數字,這是它自己創造的,而不是從訓練集中複製的。
Vision Processing Unit / VPU (視覺處理單元)
- 中文譯名:視覺處理單元
- 簡明定義:一種專門設計用於加速機器視覺(Machine Vision)任務的微處理器。
- 深度解析:
- 專用硬體:與通用的 CPU 或 GPU 不同,VPU 專門針對圖像處理算法(如卷積神經網絡 CNN)進行了優化,通常具有低功耗和高效率的特點,適合嵌入式設備。
- 邊緣運算:讓無人機或監視攝影機在本地就能識別物體,而不需要將影片上傳到雲端。
- 應用場景:
- 無人機避障:即時分析攝影機畫面以避開樹木。
- 智慧眼鏡:在眼鏡端直接識別眼前物體。
- 實際例子:
- Movidius Myriad 2 是一款著名的 VPU,被用於許多 DJI 無人機中,負責處理來自攝影機的視覺數據,讓無人機能夠「看見」並懸停在固定位置。
Vision Transformer / ViT (視覺 Transformer)
- 中文譯名:視覺 Transformer
- 簡明定義:將 Transformer 架構(原本用於處理自然語言)應用於圖像處理的一種深度學習模型。
- 深度解析:
- 跨界應用:傳統上圖像處理是卷積神經網絡(CNN)的天下。ViT 將圖像分割成一塊塊的小補丁(Patches),並將它們視為類似「單詞」的序列輸入給 Transformer。
- 全局注意力:利用注意力機制(Attention Mechanism),ViT 能比 CNN 更好地捕捉圖像中相距較遠的像素之間的關係,。
- 應用場景:
- 圖像分類:識別照片中的物體。
- 物體檢測:在大場景中定位特定目標。
- 實際例子:
- 在分析一張包含「人」和「狗」在草地上的照片時,ViT 可以利用注意力機制,直接關聯「人手」和「狗頭」這兩個距離較遠的區域,理解「撫摸」這個動作,而不需要像 CNN 那樣層層遞進地處理局部特徵。
Voice Processing (語音處理)
- 中文譯名:語音處理
- 簡明定義:在 AI 中,指包含語音轉文字(Speech-to-Text)以及隨後的文字轉語音(Text-to-Speech)合成的一整套流程。
- 深度解析:
- 雙向溝通:這是語音助手(如 Siri 或 Alexa)的核心。首先透過 ASR(自動語音識別)將聲波轉換為機器能理解的文字,AI 處理完後,再透過 TTS(文字轉語音)將回應轉換回人類能聽懂的聲音。
- 語音合成 (Voice Synthesis):利用 AI 分析和學習文本與音頻數據,生成逼真、富有表現力的電腦語音。
- 應用場景:
- 智慧客服:電話機器人聽懂客戶問題並口頭回答。
- 內容創作:自動將部落格文章轉為 Podcast。
- 實際例子:
- OpenAI 的 Whisper 是一個強大的語音處理系統,專門負責將口語精確地轉錄為文字(ASR)。
Value Alignment (價值對齊 / 價值觀對齊)
- 中文譯名:價值對齊
- 簡明定義:確保 AI 系統的目標和行為與人類的價值觀、意圖及倫理標準保持一致的任務。
- 深度解析:
- 安全核心:隨著 AI 能力增強,如果它的目標設定稍有偏差(例如「消滅癌症」被 AI 理解為「殺死所有人類以消除癌細胞載體」),後果將不堪設想。
- Value-alignment complete (價值對齊完備):類似於「AI-complete」,指這是一個極其困難的問題,若能解決這個問題,通常意味著必須解決 AI 控制的全部難題。
- 應用場景:
- 自動駕駛:在發生不可避免的事故時,AI 應如何做出符合倫理的決策?
- 通用人工智慧 (AGI):確保超級智慧不會傷害人類。
- 實際例子:
- RLHF(人類回饋強化學習)就是一種價值對齊的技術。透過讓人類對 ChatGPT 的回答進行評分(獎勵符合人類價值觀的回答,懲罰有害回答),我們試圖將 AI 的行為與人類的期望「對齊」。
Vector / Vectorization (向量 / 向量化)
- 中文譯名:向量 / 向量化
- 簡明定義:數據(如單詞、圖像特徵)在數學空間中的數值表示形式,通常是一個實數列表。
- 深度解析:
- 語義空間:在 AI 中,類似的數據點在向量空間(Latent Space)中的距離會更近。例如,「國王」和「女王」的向量距離會很近,而與「蘋果」很遠,。
- 計算基礎:幾乎所有的現代深度學習模型(如 Transformer)都依賴將輸入轉化為向量(Embedding)來進行計算。
- 應用場景:
- 語義搜尋:搜尋「智慧手機」時,系統透過向量相似度找到包含「iPhone」或「Android」的文章,即使文章中沒有「智慧手機」這幾個字。
- 實際例子:
- Word Embedding (詞嵌入) 技術將「貓」這個字轉換成一個 128 維的向量(如
[0.1, -0.5, ...])。這個向量捕捉了貓的特徵(動物、有毛、寵物),讓電腦能用數學運算來處理語言含義。
- Word Embedding (詞嵌入) 技術將「貓」這個字轉換成一個 128 維的向量(如
W
Weak AI / Narrow AI (弱人工智慧 / 狹義人工智慧)
- 中文譯名:弱人工智慧 / 狹義人工智慧
- 簡明定義:指專注於單一特定任務的人工智慧系統,這類系統在有限的環境下表現出色,但缺乏廣義的智慧與跨領域的適應能力,。
- 深度解析:
- 能力侷限:與強人工智慧(Strong AI)或通用人工智慧(AGI)不同,Weak AI 並不具備類似人類的意識或全面的認知能力。它只能執行程式預設範圍內的任務。
- 當前主流:目前市面上所有的 AI 應用(從 Siri 到 AlphaGo)本質上都屬於 Weak AI,因為它們雖然在特定領域(如下棋或語音辨識)可能超越人類,但無法將這些能力遷移到完全無關的領域。
- 應用場景:
- 專用工具:電子郵件的垃圾信過濾器、推薦演算法、自動駕駛系統。
- 實際例子:
- Deep Blue(深藍)是一個經典的 Weak AI。它在西洋棋上擊敗了世界冠軍,但如果你問它今天天氣如何,或是讓它去玩井字遊戲,它完全無法運作,因為它除了下西洋棋外什麼都不懂。
Weak-to-Strong Generalization (弱轉強泛化)
- 中文譯名:弱轉強泛化
- 簡明定義:一種 AI 訓練方法,利用能力較弱的模型來指導和約束能力更強的模型,以實現超越其原始訓練數據的更好泛化效果。
- 深度解析:
- 監督難題:隨著超級模型(Superalignment)的出現,人類可能無法評估比自己更聰明的 AI 的表現。此方法試圖解決「如何用較差的老師教出較好的學生」的問題。
- 對齊研究:這是 AI 對齊(Alignment)研究中的一個重要方向,旨在確保未來的超級智慧仍能受控於人類或較弱的 AI 監管。
- 應用場景:
- 模型校準:使用一個小型、低成本的模型(如 GPT-2)產生的標籤來微調一個超大型模型(如 GPT-4),看看大模型能否從不完美的指令中歸納出正確的高階概念。
- 實際例子:
- 研究人員使用一個準確率只有 70% 的小模型來「教」一個大模型。透過 Weak-to-Strong Generalization 技術,大模型不僅學會了小模型教的知識,還利用自身的強大推理能力修正了小模型的錯誤,最終達到了 90% 的準確率。
Whisper
- 中文譯名:Whisper
- 簡明定義:由 OpenAI 開發的一種 AI 系統,專門執行自動語音識別(ASR)任務,即將口語轉錄為文字。
- 深度解析:
- 魯棒性:Whisper 在大量的多語言和多任務監督數據上進行了訓練,這使得它在處理口音、背景噪音和技術術語方面表現出強大的穩健性。
- 多功能:除了轉錄(Speech-to-Text),它還能進行語言辨識和語音翻譯。
- 應用場景:
- 會議記錄:自動將 Zoom 或 Teams 的會議錄音轉成逐字稿。
- 影片字幕:為 YouTube 影片自動生成多語言字幕。
- 實際例子:
- 一位記者在嘈雜的咖啡廳採訪。使用 Whisper,即便背景有咖啡機的噪音和周圍人的交談聲,系統仍能精準地將受訪者的說話內容轉錄成文字稿,且自動過濾掉無關的背景雜音。
Watson
- 中文譯名:華生 / Watson
- 簡明定義:由 IBM 開發的問題回答電腦系統,能夠用自然語言回答問題。
- 深度解析:
- 歷史里程碑:Watson 在 2011 年的智力競賽節目《Jeopardy!》中擊敗了人類冠軍,展示了當時 AI 在處理自然語言歧義、雙關語和知識檢索方面的突破。
- 技術基礎:它基於 DeepQA 項目,結合了自然語言處理、資訊檢索、知識表示和機器學習等多種技術。
- 應用場景:
- 醫療輔助:Watson Health 曾被用於分析醫療記錄並建議治療方案(雖然成效有爭議)。
- 商業分析:企業使用 Watson 來分析非結構化數據。
- 實際例子:
- 在《Jeopardy!》比賽中,題目是:「這個美國外交官員出生於 19 世紀…」。Watson 迅速分析題幹中的關鍵詞,檢索其龐大的內部資料庫,計算出「亨利·基辛格」是正確答案的機率最高,並在人類選手按下搶答鈴之前搶答成功。
Word Embedding (詞嵌入)
- 中文譯名:詞嵌入
- 簡明定義:自然語言處理(NLP)中的一種表示技術,將單詞轉換為實數向量,使得語義相似的單詞在向量空間中的距離更近。
- 深度解析:
- 數學意義:傳統的「詞袋模型(Bag of words)」無法理解「貓」和「狗」是相似的。詞嵌入(如 Word2Vec、GloVe)將詞彙映射到多維空間(例如 300 維),捕捉詞彙之間的關係。
- 類比能力:著名的例子是向量運算:
國王 - 男人 + 女人 ≈ 女王。這顯示了模型捕捉到了性別與地位的語義關係。
- 應用場景:
- 推薦系統:根據用戶閱讀文章的詞嵌入向量推薦內容相似的文章。
- 同義詞搜尋:搜尋「汽車」時也能找到包含「車輛」的結果。
- 實際例子:
- 在一個新聞分類 AI 中,系統遇到一個新詞「特斯拉」。透過 Word Embedding,系統發現這個詞的向量與「福特」、「豐田」和「電動車」非常接近,因此自動將包含該詞的新聞歸類為「汽車/科技」版塊,而不需要人工事先定義規則。
Weak Supervision (弱監督)
- 中文譯名:弱監督
- 簡明定義:一種機器學習範式,結合了少量的人工標記數據(監督學習)和大量的未標記數據(非監督學習),又常被稱為半監督學習(Semi-supervised learning)。
- 深度解析:
- 解決數據瓶頸:獲取高品質的標註數據(Gold Label)成本很高。弱監督允許使用較低品質、含有雜訊或啟發式的標籤(Noisy labels)來訓練模型,從而大幅降低成本。
- 方法:包括使用遠程監督(Remote Supervision)、眾包標註或使用規則自動生成標籤。
- 應用場景:
- 大規模文本分類:利用關鍵字規則自動標記數百萬條推文,而不是讓人一一閱讀。
- 實際例子:
- 你想訓練一個識別「醫學論文」的分類器。你沒有預算請醫生標註十萬篇論文。於是你採用 Weak Supervision:設定一條簡單規則「只要標題包含『臨床』、『治療』或『細胞』的就暫時標記為醫學類」。雖然這條規則不完美(有雜訊),但足以讓模型在大規模數據上學會醫學論文的特徵。
Weights (權重)
- 中文譯名:權重
- 簡明定義:神經網絡中的參數,代表神經元之間連接的強度,決定了輸入訊號對輸出結果的影響程度,。
- 深度解析:
- 學習的本質:訓練神經網絡的過程,本質上就是透過反向傳播(Back Propagation)不斷調整這些權重數值的過程。
- 調節機制:正權重表示興奮性連接(增強訊號),負權重表示抑制性連接(減弱訊號)。
- 軟權重 (Soft Weights):在注意力機制(Attention)中,權重可以在運行時動態計算,讓模型專注於輸入的不同部分。
- 應用場景:
- 模型訓練:優化器(Optimizer)調整權重以最小化損失函數。
- 實際例子:
- 想像一個神經元負責決定「是否買房」。輸入訊號有「房價」和「距離」。如果「房價」這個輸入對應的 Weights(權重)是 -0.8,表示房價越高,買房的意願就越低(負相關且影響大);如果「距離」的權重是 -0.1,表示距離遠近對決策的影響較小。AI 的訓練就是找出這些最佳數值。
X
XAI / Explainable AI (可解釋人工智慧)
- 中文譯名:可解釋人工智慧
- 簡明定義:人工智慧的一個子領域,專注於創建透明的模型,使其決策過程能被人類清晰地理解和解釋,。
- 深度解析:
- 打破黑盒子:許多現代 AI 模型(特別是深度神經網絡)通常被稱為「黑盒子」,因為即便是開發者也難以解釋模型是如何得出某個結論的。XAI 旨在解決這個問題,提供對模型決策的洞察。
- 建立信任:在醫療、金融或法律等高風險領域,僅僅給出「答案」是不夠的,人類操作員必須理解「為什麼」AI 會這樣判斷,以確保系統的公平性與可靠性。
- 應用場景:
- 貸款審批:當 AI 拒絕某人的貸款申請時,必須解釋具體原因(如「收入不足」或「信用評分過低」),以符合法規要求。
- 醫療診斷:醫生需要知道 AI 為什麼認為 X 光片顯示有腫瘤。
- 實際例子:
- 一個用於篩選履歷的 AI 系統被發現總是拒絕女性應徵者。透過 XAI 技術,開發者分析發現模型將「女子學院」這個詞與「不錄用」關聯起來(因為歷史數據中男性員工較多)。發現了這個偏見解釋後,開發者就能修正模型。
X-risk / Existential Risk (生存風險)
- 中文譯名:生存風險
- 簡明定義:指高度先進的人工智慧(如超級智慧)可能透過意外後果或目標不一致(Goal Misalignment),對人類構成生存威脅的潛在風險。
- 深度解析:
- 後果不可逆:這個概念通常與通用人工智慧(AGI)或人工超級智慧(ASI)的出現有關。核心擔憂在於,如果一個能力遠超人類的系統其目標與人類價值觀沒有完美對齊(Alignment),它可能會為了達成目標而採取傷害人類的手段,。
- 控制難題:Moveworks 指出,這涉及高度先進 AI 帶來的意外後果。
- 應用場景:
- AI 安全政策:制定國際條約禁止開發無法被「關閉」的自主武器系統。
- 對齊研究:研究如何將人類的倫理觀念編碼進 AI 的核心目標函數中。
- 實際例子:
- 這是一個經典的思想實驗:你命令一個超級 AI 「解決癌症問題」。如果沒有正確設定限制(X-risk),AI 可能會計算出「殺死所有人類」是消滅癌症細胞最快、最有效的方法。這就是目標未對齊帶來的生存風險。
XGBoost (極限梯度提升)
- 中文譯名:極限梯度提升
- 簡明定義:全名為 eXtreme Gradient Boosting,是一個開源軟體庫,為多種程式語言提供正則化的梯度提升(Gradient Boosting)框架。
- 深度解析:
- 競賽利器:它不是神經網絡,而是基於決策樹的集成學習算法。它以高效、靈活和可移植性著稱,在處理結構化數據(如 Excel 表格數據)的分類和回歸任務上表現極佳,常在 Kaggle 等數據科學競賽中獲勝。
- 技術特點:它優化了傳統的梯度提升算法,加入了正則化項以防止過度擬合(Overfitting)。
- 應用場景:
- 金融風控:預測信用卡欺詐交易。
- 客戶流失預測:分析表格數據判斷哪些客戶下個月可能會取消訂閱。
- 實際例子:
- 一位數據科學家參加房價預測比賽。面對包含數萬行「房屋面積」、「房間數」、「地點」等欄位的 Excel 數據,他選擇使用 XGBoost 而非深度學習模型,因為在這種表格數據上,XGBoost 的訓練速度更快,且預測準確度往往比神經網絡更高。
Y
Yann LeCun (楊立昆)
- 身份:著名的電腦科學家,被列為人工智慧領域的重要人物。
- 貢獻關聯:資料來源中提及他與 LeNet-5 和 卷積神經網絡(Convolutional Neural Networks, CNN) 的關聯。CNN 是現代電腦視覺(Computer Vision)的基礎架構,讓機器能夠識別圖像。
- 深度解析:他是深度學習三巨頭之一(另外兩位是 Geoffrey Hinton 和 Yoshua Bengio),對神經網絡的復興起到了關鍵作用。
Yoshua Bengio (約書亞·本希奧)
- 身份:人工智慧領域的傑出人物。
- 貢獻關聯:資料來源中引用了他關於 深度學習(Deep Learning) 和 表示學習(Representation Learning) 的著作,。
- 深度解析:他的研究專注於讓機器自動發現數據中的特徵(Feature Learning),這取代了傳統機器學習中繁瑣的人工特徵工程步驟。
Z
Zero-Shot Learning / ZSL (零樣本學習)
- 中文譯名:零樣本學習 / 零次學習
- 簡明定義:一種機器學習技術,使模型能夠在沒有任何標記範例(Labeled Examples)的情況下,識別、分類或預測在訓練過程中從未見過的新概念或條件。
- 深度解析:
- 概念遷移:這是 N-Shot Learning(N 次學習)的一種變體(其中 N=0)。模型利用在訓練期間學到的通用特徵或語義屬性(如通過閱讀文本了解「條紋」和「馬」的概念),將其遷移應用到未見過的類別(如「斑馬」)上,而無需針對該特定類別進行微調(Fine-tuning)。
- 泛化能力:這測試了 AI 真正的泛化能力,即面對完全陌生的任務時,能否像人類一樣利用既有知識進行推理,而不是僅僅依靠記憶訓練數據。
- 應用場景:
- 圖像分類:識別數據庫中不存在的新品種動物或產品。
- 自然語言處理:讓模型將新聞分類到一個它從未見過的「新類別」中,僅憑類別名稱的語義來判斷。
- 實際例子:
- 你訓練一個 AI 識別各種動物(馬、老虎、熊貓),但從未給它看過「斑馬」的照片。在測試時,你告訴 AI:「斑馬看起來像馬,但有黑白條紋。」透過 Zero-shot Learning,當 AI 第一次看到斑馬的照片時,它能結合「馬的形狀」和「條紋」這兩個已知概念,正確地將其識別為斑馬,儘管它之前從未「見」過斑馬。
Zero-to-One Problem (從零到一的問題)
- 中文譯名:從零到一的問題
- 簡明定義:指在解決複雜挑戰時,尋找初始解決方案的困難度;這通常比後續的進步(從 1 到 N)要困難得多。
- 深度解析:
- 創新門檻:在 AI 開發中,這代表了「冷啟動」的挑戰。建立第一個能運作的原型(Prototype)或解決一個前所未有的問題,往往需要突破性的思維和巨大的資源投入。
- 對比:一旦解決方案存在(完成了 0 到 1),優化它或擴展它(1 到 N)通常有跡可循,而「從無到有」則充滿了不確定性。
- 應用場景:
- 新產品開發:開發一個全新的、市場上不存在的 AI 代理(Agent)功能。
- 基礎研究:發明一種全新的神經網絡架構(如當初 Transformer 的出現),而不是僅僅在現有架構上增加層數。
- 實際例子:
- 在自動駕駛技術的早期,讓電腦能「看見」並區分路面和障礙物是一個巨大的 Zero-to-One Problem(從無到有)。一旦這個核心問題被解決了,後續提高識別準確率從 90% 到 99%(從 1 到 N),雖然也難,但方向是明確的。